Black Friday Spotlight: Practical Haskell
How do you actually do something in Haskell? A programming language is only helpful if we can use it to solve real problems. Perhaps you've written up some neat and tidy solutions to small problems with Haskell. But does the language actually have the libraries and tools to build useful programs?
The answer to this question is a resounding Yes! Not only does Haskell have useful libraries for practical problems, but the "Haskell Approach" to these problems often has clear advantages! For instance, in Haskell you can:
- Write database queries that are type-safe, interoperating seamlessly with well-defined Haskell types.
- Define a web server where the API is clearly laid out and defined in terms of Haskell types.
- Link your Haskell types to frontend types that will populate your Web UI
- Organize "effects" within your system so that the capabilities of different functions are explicitly defined and known to your program at compile-time.
- Use monads to describe a test case in plan language.
These ideas can supercharge your Haskell abilities! But they aren't necessarily easy to pick up. It takes a fair amount of commitment to learn them well enough to use in your own projects.
Luckily, Monday Morning Haskell has a great tool for you to learn these skills! Our Practical Haskell Course will teach you how to build a functional application that integrates systems like databases, web servers, frontend web pages, and behavioral tests.
If this sounds like exactly what you've been looking for to rapidly improve your Haskell, head to the course page to get started!
If you're curious for more details, head to our course description page to learn about what you can expect in the course.
Don't forget, you've got a couple more days to take advantage of our Black Friday Sale! You can use the code BlackFriday22 to get 20% off any of our courses, including Practical Haskell. If you subscribe to our mailing list, you can get an even better code for 30% off! So don't miss out on those savings!
Black Friday Spotlight: Effectful Haskell!

Monads are a tricky subject. So tricky in fact, that most of the material out there about them is either a.) focused on surface level questions like "what is a monad" or b.) aimed at really abstract details like "how do monads relate to category theory". But there's not nearly as much content about how to use monads in a larger project context.
It's one thing to know what a monad is and how to write basic monadic code. But this will only give you a small amount of the power of monads! As you build more complex Haskell programs, monads can make your life a lot easier...if you know how to use them!
So how does one learn these techniques?
The answer of course, is with hands on practice. And Monday Morning Haskell has just the tool you need for that! Effectful Haskell is our short course aimed at teaching you the techniques to use monads to organize all the various effects in your system. You'll learn:
- How to construct a monad that encapsulates all the various effects in your system.
- How to use monad classes to perform IO actions while limiting the scope of your different functions.
- How free monads can make it outrageously simple to configure and modify the behavior of your program, like changing your underlying database layer, or adding mock test effects.
- And as an extra bonus, you'll also get a primer on how to deploy a Haskell application to the web using Heroku!
If this checks all the boxes for what you'd like to learn, head over to the course page to get started!
To learn more details, including FAQ, you can head to our course description page.
Since our Black Friday sale is going on, don't forget you can use the code BlackFriday22 to get 20% off all courses! This offer ends next Monday, so don't miss out!
Black Friday Spotlight: Making Sense of Monads!

There are probably a thousand blog posts, articles, and videos out there trying to teach what monads are. Some are too simple to really tell you what's going on ("A monad is like a burrito!"). Some are too complicated for anyone who isn't already well versed in abstract math ("A monad is a monoid is the category of endofunctors!").
All of them try to pass on some of the fundamental knowledge. But virtually none of them provide you with the tools you really need to use monads in your own code. For that, you need practical experience that involves writing the code yourself.
Our Making Sense of Monads course is designed to provide just that. In this course, you'll learn:
- Fundamental knowledge about simpler abstract structures that will help you understand monads
- How to understand monadic syntax in Haskell
- How to use all of the most common monads in Haskell
And best of all, you'll get a chance to practice your skills with programming exercises, and some project-based code.
If you think this sounds like the tool you need to finally understand monads, head to the course page to get started!
If you'd like to learn more about what you can expect from the course, you can read about the course outline on this page!
And don't forget about our Black Friday sale! You can get 20% off all our courses by using the code BLACKFRIDAY22! If you subscribe to our mailing list, you'll get an even better code for 30% off, so don't miss out!
Black Friday Spotlight: Haskell From Scratch!
If you're on this site, you've probably read quite a bit about Haskell. But perhaps you've never written any of it yourself. Or maybe you tried some tutorial, and got a few lines to work. But you don't know how you would actually build a project in Haskell.
If you think it's time to change that, keep reading!
Our Haskell From Scratch Course is an awesome tool for newcomers to Haskell, focusing on all the questions you'll have when you're just starting out:
- How do I build and run Haskell code?
- How does Haskell's type system work?
- What is a monad?
- How is problem solving different in Haskell?
You'll learn about all of this and more in Haskell From Scratch. If this sounds like what you're looking for, head to the course sales page now!
If you want to know more about the course, head to this page for a more in depth outline!
Just remember, we're currently having our Black Friday sale! So you can get 20% off any of our courses by using the code BLACKFRIDAY22 when you check out. Even better, you can extend that savings to 30% when you subscribe to our mailing list! So don't miss out!
Black Friday Course Sale!
This whole blog is dedicated to helping you to learn Haskell. And learning any programming language is hard, most of all one that doesn't fit most of the conventions in other languages! While there are hours and hours of content for you to read on Monday Morning Haskell, reading alone unfortunately won't make you the best programmer you can be.
So what's actually the best way to get better at programming?
Improving at any technical skill requires commitment and hands-on experience. You have to make a purposeful investment - setting aside time and energy to this task. And you have to spend that time actually doing it, rather than simply reading about it.
And this is why Monday Morning Haskell has a diverse array of online courses to give you hands-on experience learning new Haskell concepts and writing your own code. Every course consists of video lectures paired with detailed programming exercises, usually including unit tests. Certain courses also include screencasts where you can observe certain steps of the coding process before trying them for yourself. A couple courses also have a project component where you can add your own code to something with a practical use!
These courses are great tools to take your Haskell skills to the next level, whether you're still a beginner or a more advanced Haskeller. And today is the best time to do it, because today is the start of our Black Friday Sale. All courses are available for 20% off their normal price with the code BLACKFRIDAY22. Plus, if you subscribe to our monthly mailing list, you can get an even better discount for 30% off.
Head to our courses page to take a look at our options! Over the next week, we'll spotlight each of the different courses here on the blog!
What's New?
Now perhaps you've taken one of our courses in the past and you're curious if anything's changed. And, in fact, we've made a few updates to improve your student experience!
GHC 9.0.2
All courses are now updated to use GHC 9.0.2 (generally with Stack resolver 19.24). This means they are more up to date with the latest Haskell libraries. It also is significant for students with newer MacOS hardware. Older GHC versions often can't compile on new Macs without some odd hacks. All of our courses should now work out of the box on these machines.
Zip File Delivery
Previously, our courses would always require students to get added as collaborators on a private GitHub repository before they could start coding. All course code is now also available through .zip files so you can get started right away!
Answers Branches
A common request in the past was to have reference answers available for students who got stuck. We started incorporating this for newer courses, and have now retroactively applied it to older courses as well. At the end of every module, you should be able to find a .zip file with our recommended answers in case you get stuck.
Exercise Revisions
Finally, exercise descriptions have been revised for clarity!
Conclusion
As a last note, all our courses are lifetime access and come with a 30-day refund guarantee. So don't miss out! Subscribe to the mailing list to get the maximum discount! (Or just use BLACKFRIDAY22 to get 20% off any of our courses)
Dijkstra Token Puzzle - Video Walkthrough
Today’s our final video walkthrough from Advent of Code 2021. We’re going back over the Day 23 puzzle that involved finding the optimal token path. Here’s the writeup, and here’s the code. And of course, here’s the video!
Make sure to subscribe if you’ve enjoyed these videos! We’ll have a major offer next week that’s specifically for subscribers!
Once we hit December 1st, I’ll be trying to do daily videos for this year’s Advent of Code, so stay tuned for those as well!
An Unusual Application for Dijkstra
Today will be the final write-up for a 2021 Advent of Code problem. It will also serve as a capstone for the work on Dijkstra's algorithm I did back in the summer! This problem uses Dijkstra's algorithm, but in a more unusual way! We'll be working on Day 23 from last year. And for my part, I'll say that days 21-24 were all extremely challenging, so this is one of the "final boss" puzzles!
Like our previous write-ups, this is an In-Depth walkthrough, and it's a long one! So get ready for some details! The code is available on GitHub as always so you can follow along.
Problem Statement
For this puzzle, we start with a set of tokens divided into 4 rooms with a hallway allowing them to move around.
#############
#...........#
###B#C#B#D###
#A#D#C#A#
#########Our goal is to rearrange the tokens so that the A tokens are both in the first room, the B tokens are in the second room, the C tokens are in the third room, and the D tokens are in the fourth room.
#############
#...........#
###A#B#C#D###
#A#B#C#D#
#########However, there are a lot of restrictions on the possible moves. First, token's can't move past each other in the hall (or rooms). If D comes out of the fourth room first, we cannot then move the A in that room anywhere to the left. It could only go to a space on the right.
#############
#.......D...#
###B#C#B#.###
#A#D#C#A#
#########Next, each token can only make two moves total. It can move into the hallway once, and then into its appropriate room. It can't take a side journey into a different room to make space for other tokens to pass.
On top of this, each token spends a certain amount of "power" (or "energy") to move per space. The different tokens spend a different amount of energy:
A = 1
B = 10
C = 100
D = 1000So from the start position, we could spend 2000 energy to move D up to the right, and then only 9 energy to move A all the way to the left side.
#############
#.A.......D.#
###B#C#B#.###
#A#D#C#.#
#########Our goal is to get the desired configuration with the least amount of energy expended.
For the "harder" version of this problem, not much changes. We just have 4 tokens per room, so more maneuvering steps are required.
#############
#...........#
###B#C#B#D###
#D#C#B#A#
#D#B#A#C#
#A#D#C#A#
#########Solution Approach
The surprising solution approach (at least I was surprised when I realized it could work), is to treat this like a graph problem. Each "state" of the puzzle represents a node in the graph. Any given state has "edges" representing transitions to future states of the puzzle. The edges are weighted by how much energy is required in the transition.
Once we view the problem in this way, the solution is simple. We apply a "shortest path" algorithm (like Dijkstra's) using the "end" state of the puzzle as the destination. We'll get the series of moves that uses the least total energy.
For example, the first starting solution would represent one node. It would have an edge to this following puzzle state, with a weight of 2000, since a D is moving two spaces.
#############
#.........D.#
###B#C#B#.###
#A#D#C#A#
#########There are some potential questions about the scale of this problem. If the potential number of nodes is too high, even Dijkstra's algorithm could take too long. And if the tokens could be placed arbitrarily anywhere in the puzzle space, our upper bound might be a factorial number like 23-P-16. This would be too large.
However, as a practical matter, the solution space is much smaller than this because of the many restrictions on how tokens can actually move. So we'll end up with a solution space that is still large but not intractable.
Solution Outline
As we start to outline our solution, we need to start by considering which Dijkstra library function we'll use. In order to allow monadic actions in our functions (such as logging), we'll use dijkstraM, which has the following type signature:
dijkstraM ::
(Monad m, Foldable f, Num cost, Ord cost, Ord state) =>
(state -> m (f state)) ->
(state -> state -> m cost) ->
(state -> m bool) ->
state ->
m (Maybe (cost, [state]))To make this work, we need to pick the types we'll use for state and cost. For the cost, we can rely on a simple Int. For the state, we'll create a custom GraphState type that will represent the state of the solution at a particular point in time.
data GraphState = ...We'll expand more on exactly what information goes into this type as we go along. But now that we've defined our type, we can define the three functions that we'll use as inputs to dijkstraM:
getNeighbors :: (MonadLogger m) => GraphState -> m [GraphState]
getCost :: (MonadLogger m) => GraphState -> GraphState -> m Int
isComplete :: (MonadLogger m) => GraphState -> m BoolWe can (and will) add at least one more argument to partially apply, but still, this lets us outline what a full invocation of the function might look like:
solution :: (MonadLogger m) => GraphState -> m (Maybe (Int, [GraphState])
solution initialState = dijkstraM getNeighbors getCost isComplete initialStateCompleteness Check
So now let's start filling in these functions. We'll start with the completeness check, since that's the easiest. Because this check is run fairly often, we want to make it as quick as possible. So instead of doing a full completeness check on the state each time we call it, we'll store a specific field in the graph state called roomsFull.
data GraphState = GraphState
{ roomsFull :: Int -- Initially 0, increments when we finish a room
...
}This field will be 0 when we initialize the state, and whenever we "complete" a room in our search path, we'll bump the number up. Checking for completeness then is as simple as checking that we've completed all 4 rooms.
isComplete :: (MonadLogger m) => GraphState -> m Bool
isComplete gs = return (roomsFull gs == 4)Cost
It would be more convenient to combine the cost with the neighbors function, like in dijkstraAssoc. But we don't have this option if we want to use a monad. Calculating the cost between two raw graph states would be a little tricky, since we'd have to go through a lot of cases to see what has actually changed.
However, it gets easier if we include the "last move" as part of the GraphState type. So let's start defining what a Move looks like. To start, we'll include a NoMove constructor for the initial position, and we'll make a note that the GraphState will include this field.
data Move =
NoMove |
...
data GraphState = GraphState
{ lastMove :: Move
, roomsFull :: Int
...
}So how do we describe a move? Because the rules are so constrained, we can be sure every move has the following:
- A particular token that is moving.
- A particular "hall space" that it is moving to or from.
- A particular "room" that it is moving to or from.
Each of these concepts is easily enumerated, so let's make some Enum types that are also indexable (we'll see why soon):
data Token = A | B | C | D
deriving (Show, Eq, Ord, Enum, Ix)
data Room = RA | RB | RC | RD
deriving (Show, Eq, Ord, Enum, Ix)
-- Can never occupy spaces above the room like H3, H5, H7, H9
data HallSpace = H1 | H2 | H4 | H6 | H8 | H10 | H11
deriving (Show, Eq, Ord, Enum, Ix)Now we can describe the Move constructor with these three items, as well as two more pieces of data. First, an Int paired with the room describing the "slot" of the room involved. For example, the top "slot" of a room would be 1, the space below it would be 2, and so on. Finally, we'll include a Bool telling us if the move is leaving the room (True) or entering the room (False). This won't be necessarily for calculations, but it helps with debugging.
data Move =
NoMove |
Move Token HallSpace (Room, Int) Bool
deriving (Show, Eq, Ord)So what is the cost of a move? We have to calculate the distance, and we have to know the power multiplier. So let's make two constant arrays that we'll reference. First, let's match each token to its multiplier:
tokenPower :: A.Array Token Int
tokenPower = A.array (A, D) [(A, 1), (B, 10), (C, 100), (D, 1000)]Now we want to match each pair of "hall space" and "room" with a distance measurement. This tells us how many moves it takes to get from the hall space to the space above the room. For example, the first hall space requires 2 moves to get to room A and 4 to get to room B, while the second space only requires 1 and 3 moves, respectively:
hallRoomDistance :: A.Array (HallSpace, Room) Int
hallRoomDistance = A.array ((H1, RA), (H11, RD))
[ ((H1, RA), 2), ((H1, RB), 4), ((H1, RC), 6), ((H1, RD), 8)
, ((H2, RA), 1), ((H2, RB), 3), ((H2, RC), 5), ((H2, RD), 7)
...
]Here's what the complete array looks like:
hallRoomDistance :: A.Array (HallSpace, Room) Int
hallRoomDistance = A.array ((H1, RA), (H11, RD))
[ ((H1, RA), 2), ((H1, RB), 4), ((H1, RC), 6), ((H1, RD), 8)
, ((H2, RA), 1), ((H2, RB), 3), ((H2, RC), 5), ((H2, RD), 7)
, ((H4, RA), 1), ((H4, RB), 1), ((H4, RC), 3), ((H4, RD), 5)
, ((H6, RA), 3), ((H6, RB), 1), ((H6, RC), 1), ((H6, RD), 3)
, ((H8, RA), 5), ((H8, RB), 3), ((H8, RC), 1), ((H8, RD), 1)
, ((H10, RA), 7), ((H10, RB), 5), ((H10, RC), 3), ((H10, RD), 1)
, ((H11, RA), 8), ((H11, RB), 6), ((H11, RC), 4), ((H11, RD), 2)
]Now calculating the cost is fairly straightforward. We get the distance to the room, add the slot within the room, and then multiply this by the power multiplier.
getCost :: (MonadLogger m) => GraphState -> GraphState -> m Int
getCost _ gs = if lastMove gs == NoMove
then return 0
else do
let (Move token hs (rm, slot) _) = lastMove gs
let mult = tokenPower A.! token
let distance = slot + hallRoomDistance A.! (hs, rm)
return $ mult * distanceFinishing the Graph State
Our solution is starting to take on a bit more shape, but we need to complete our GraphState type before we can make further progress. But now armed with the notion of a Token, we can fill in the remaining fields that describe it. Each room has a list of tokens that are currently residing there. And then each hall space either has a token there or not, so we have Maybe Token fields for them.
data GraphState = GraphState
{ lastMove :: Move
, roomsFull :: Int
, roomA :: [Token]
, roomB :: [Token]
, roomC :: [Token]
, roomD :: [Token]
, hall1 :: Maybe Token
, hall2 :: Maybe Token
, hall4 :: Maybe Token
, hall6 :: Maybe Token
, hall8 :: Maybe Token
, hall10 :: Maybe Token
, hall11 :: Maybe Token
}
deriving (Show, Eq, Ord)Sometimes it will be useful for us to access parts of the state in a general way. We might want a function to access "one of the rooms" or "one of the hall spaces". Some day, I might revise my solution to use proper Haskell "Lenses", which would be ideal for this problem. But for now we'll define a couple simple type aliases for a RoomLens to access the tokens in a general room, and a HallLens for looking at a general hall space.
type RoomLens = GraphState -> [Token]
type HallLens = GraphState -> Maybe TokenOne last piece of boilerplate we'll want will be to have "split lists" for each room. Each of these is a tuple of two lists. The first list is the hall spaces to the "left" of that room, and the second has the hall spaces to the "right" of the room.
These lists will help us answer questions like, "how many empty hall spaces can we move to from this room moving left?", or "what is the first token to the right of this room?" For these to be useful, each hall space should also include the "lens" into the GraphState, so we can examine what token lives there.
For example, room A has H2 and H1 to its left (in that order), and then H4, H6, H8, H10 and H11 to its right. We'll match each HallSpace with its HallLens, so H1 combines with the hall1 field from GraphState, and so on.
aSplits :: ([(HallLens, HallSpace)], [(HallLens, HallSpace)])
aSplits =
( [(hall2, H2), (hall1, H1)]
, [(hall4, H4), (hall6, H6), (hall8, H8), (hall10, H10), (hall11, H11)]
)Here's what the rest of those look like:
bSplits :: ([(HallLens, HallSpace)], [(HallLens, HallSpace)])
bSplits =
( [(hall4, H4), (hall2, H2), (hall1, H1)]
, [(hall6, H6), (hall8, H8), (hall10, H10), (hall11, H11)]
)
cSplits :: ([(HallLens, HallSpace)], [(HallLens, HallSpace)])
cSplits =
( [(hall6, H6), (hall4, H4), (hall2, H2), (hall1, H1)]
, [(hall8, H8), (hall10, H10), (hall11, H11)]
)
dSplits :: ([(HallLens, HallSpace)], [(HallLens, HallSpace)])
dSplits =
( [(hall8, H8), (hall6, H6), (hall4, H4), (hall2, H2), (hall1, H1)]
, [(hall10, H10), (hall11, H11)]
)It would be easy enough to use a common function with splitAt to describe all of these. But once again, we'll reference these many times throughout the solution, so using constants instead of requiring function logic could help make our code faster.
Moves from a Particular Room
Now it's time for the third and largest piece of the puzzle: calculating the "next" states, or the "neighboring" states of a particular graph state. This means determining what moves are possible from a particular position. This is a complex problem that we'll have to keep breaking down into smaller and smaller parts.
We can first observe that every move involves one room and the hallway - there are no moves from room to room. So we can divide the work by considering all the moves concerning one particular room. Then there are three cases for each room:
- The room is complete; it is full of the appropriate token.
- The room is empty or partially full of the appropriate token.
- The room has mismatched tokens inside.
In case 1, we'll propose no moves involving this room. In case 2, we will try to find the appropriate token in the hall and bring it into the room (from either direction). In case 3, we will consider all the ways to move a token out of the room.
We'll do all this in a general function roomMoves. This function needs to know the room size, the appropriate token for the room, the appropriate lens for accessing the room, and finally, the split list corresponding to the room. This leads to a long type signature, but each parameter has its role:
roomMoves ::
(MonadLogger m) =>
Int ->
Token ->
Room ->
RoomLens ->
([(HallLens, HallSpace)], [(HallLens, HallSpace)]) ->
GraphState ->
m [GraphState]
roomMoves rs tok rm roomLens splits gs = ...For getNeighbors, all we have to do is invoke this function once for each room and combine the results.
getNeighbors :: (MonadLogger m) => Int -> GraphState -> m [GraphState]
getNeighbors rs gs = do
arm <- roomMoves rs A RA roomA aSplits gs
brm <- roomMoves rs B RB roomB bSplits gs
crm <- roomMoves rs C RC roomC cSplits gs
drm <- roomMoves rs D RD roomD dSplits gs
return $ arm <> brm <> crm <> drmNow back to roomMoves. Let's start by defining the three cases mentioned above. The first case is easy to complete.
roomMoves rs tok rm roomLens splits gs
| roomLens gs == replicate rs tok = return []
| all (== tok) (roomLens gs) = ...
| otherwise = ...Now let's consider the second case. We want to search each direction from this room to try to find a hall space containing the matching token. We can do this with a recursive helper function. In the base case, we're out of hall spaces to search, so we return Nothing:
findX :: Token -> GraphState -> [(HallLens, HallSpace)] -> Maybe HallSpace
findX _ _ [] = Nothing
findX tok gs ((lens, space) : rest) = ...Then there are three simple cases for what to do with the next space. If we have an instance of the token, return the space. If we have a different token, the answer is Nothing (we are blocked). If there is no token there, we continue the search recursively.
findX :: Token -> GraphState -> [(HallLens, HallSpace)] -> Maybe HallSpace
findX _ _ [] = Nothing
findX tok gs ((lens, space) : rest)
| lens gs == Just tok = Just space
| isJust (lens gs) = Nothing
| otherwise = findX tok gs restUsing our split lists, we can find the potential spaces on the left and the right by applying our findX helper.
roomMoves rs tok rm roomLens splits gs
| roomLens gs == replicate rs tok = return []
| all (== tok) (roomLens gs) = do
let maybeLeft = findX tok gs (fst splits)
maybeRight = findX tok gs (snd splits)
halls = catMaybes [maybeLeft, maybeRight]
...
| otherwise = ...For right now, let's just worry about constructing the Move object. Later on, we'll fill out a function to apply this move:
applyHallMove :: Int -> Token -> RoomLens -> GraphState -> Move -> GraphStateSo to finish the case, we get the "slot" number to move to by considering the length of the room currently. Then we construct the Move, and apply it against our two possible outcomes.
roomMoves rs tok rm roomLens splits gs
| roomLens gs == replicate rs tok = return []
| all (== tok) (roomLens gs) = do
let maybeLeft = findX tok gs (fst splits)
maybeRight = findX tok gs (snd splits)
halls = catMaybes [maybeLeft, maybeRight]
slot = rs - length (roomLens gs)
moves = map (\h -> Move tok h (rm, slot) False) halls
return $ map (applyHallMove rs tok roomLens gs) moves
| otherwise = ...Moves Out of the Room
Now let's consider the third case - moving a token out of a room. This requires finding as many consecutive "empty" hall spaces in each direction as we can. This will be another recursive helper like findX:
findEmptyHalls :: GraphState -> [(HallLens, HallSpace)] -> [HallSpace] -> [HallSpace]
findEmptyHalls _ [] accum = accum
findEmptyHalls gs ((lens, space) : rest) accum = ...Once we hit a Just token value in the graph state, we can return our accumulated list. But otherwise we keep recursing.
findEmptyHalls :: GraphState -> [(HallLens, HallSpace)] -> [HallSpace] -> [HallSpace]
findEmptyHalls _ [] accum = accum
findEmptyHalls gs ((lens, space) : rest) accum = if isJust (lens gs) then accum
else findEmptyHalls gs rest (space : accum)Now we can apply this back in our roomMoves function with both sides of the splits.
roomMoves rs tok rm roomLens splits gs
| roomLens gs == replicate rs tok = return []
| all (== tok) (roomLens gs) = ...
| otherwise = do
let (topRoom : restRoom) = roomLens gs
halls = findEmptyHalls gs (fst splits) [] <> findEmptyHalls gs (snd splits) []
...Once again then, we calculate the "slot" value and construct the new move using each of the hall spaces. Notice that the slot calculation is different. We want to subtract the length of the "rest" of the room from the room size, since this gives the appropriate slot value.
roomMoves rs tok rm roomLens splits gs
| roomLens gs == replicate rs tok = return []
| all (== tok) (roomLens gs) = ...
| otherwise = do
let (topRoom : restRoom) = roomLens gs
halls = findEmptyHalls gs (fst splits) [] <> findEmptyHalls gs (snd splits) []
slot = rs - length restRoom
moves = map (\h -> Move topRoom h (rm, slot) True) halls
...Then, as before, we'll assume we have a helper to "apply" the move, and return the new graph states. Notice this time, we set the move flag as True, since the move is coming out of the room.
applyRoomMove :: GraphState -> Token -> Move -> GraphState
applyRoomMove = ...
roomMoves rs tok rm roomLens splits gs
| roomLens gs == replicate rs tok = return []
| all (== tok) (roomLens gs) = ...
| otherwise = do
let (topRoom : restRoom) = roomLens gs
halls = findEmptyHalls gs (fst splits) [] <> findEmptyHalls gs (snd splits) []
slot = rs - length restRoom
moves = map (\h -> Move topRoom h (rm, slot) True) halls
return $ map (applyRoomMove gs tok) movesNow let's work on these two "apply" helpers. Each will take the current state and the Move and construct the new GraphState.
Applying moves
We'll start by applying the move from the room. Of course, for the NoMove case, we return the original state.
applyRoomMove :: GraphState -> Move -> GraphState
applyRoomMove gs NoMove = gs
applyRoomMove gs m@(Move token h (rm, slot) _) = ...Now with all our new information, we'll update the GraphState in two stages, because this will require two case statements. First, we'll update the hall space to contain the moved token. We'll also place the move m into the lastMove spot.
applyRoomMove :: GraphState -> Move -> GraphState
applyRoomMove gs NoMove = gs
applyRoomMove gs m@(Move token h (rm, slot) _) =
let gs2 = case h of
H1 -> gs {hall1 = Just token, lastMove = m}
H2 -> gs {hall2 = Just token, lastMove = m}
H4 -> gs {hall4 = Just token, lastMove = m}
H6 -> gs {hall6 = Just token, lastMove = m}
H8 -> gs {hall8 = Just token, lastMove = m}
H10 -> gs {hall10 = Just token, lastMove = m}
H11 -> gs {hall11 = Just token, lastMove = m}
in ...Now we need to modify the room to drop the top token. Unfortunately, we can't actually use a RoomLens argument in conjunction with record syntax updating, so this needs to be a case statement as well. With proper lenses, we could probably simplify this.
applyRoomMove :: GraphState -> Token -> Move -> GraphState
applyRoomMove gs roomToken NoMove = gs
applyRoomMove gs roomToken m@(Move token h (rm, slot) _) =
let gs2 = case h of
H1 -> gs {hall1 = Just token, lastMove = m}
H2 -> gs {hall2 = Just token, lastMove = m}
H4 -> gs {hall4 = Just token, lastMove = m}
H6 -> gs {hall6 = Just token, lastMove = m}
H8 -> gs {hall8 = Just token, lastMove = m}
H10 -> gs {hall10 = Just token, lastMove = m}
H11 -> gs {hall11 = Just token, lastMove = m}
in case rm of
RA -> gs2 { roomA = tail (roomA gs)}
RB -> gs2 { roomB = tail (roomB gs)}
RC -> gs2 { roomC = tail (roomC gs)}
RD -> gs2 { roomD = tail (roomD gs)}That's all for applying a move from the room. Applying a move from the hall into the room is similar. But we have the extra task of determining if the destination room is now complete. So in this case we actually can make use of the RoomLens.
applyHallMove :: Int -> RoomLens -> GraphState -> Move -> GraphState
applyHallMove rs roomLens gs NoMove = gs
applyHallMove rs roomLens gs m@(Move token h (rm, slot) _) = ...As before, we start by updating the hall space (now it's Nothing) and the lastMove field. We'll also update the finishedCount on this update step.
applyHallMove :: Int -> RoomLens -> GraphState -> Move -> GraphState
applyHallMove rs roomLens gs NoMove = gs
applyHallMove rs roomLens gs m@(Move token h (rm, slot) _) =
let gs2 = case h of
H1 -> gs {hall1 = Nothing, lastMove = m, roomsFull = finishedCount}
H2 -> gs {hall2 = Nothing, lastMove = m, roomsFull = finishedCount}
H4 -> gs {hall4 = Nothing, lastMove = m, roomsFull = finishedCount}
H6 -> gs {hall6 = Nothing, lastMove = m, roomsFull = finishedCount}
H8 -> gs {hall8 = Nothing, lastMove = m, roomsFull = finishedCount}
H10 -> gs {hall10 = Nothing, lastMove = m, roomsFull = finishedCount}
H11 -> gs {hall11 = Nothing, lastMove = m, roomsFull = finishedCount}
in ...
where
finishedCount = ...How do we implement the finishedCount? It's not too difficult. We can easily assess if it's finished by checking the roomLens on the original state and seeing if it's equal to "Room Size minus 1". Then the finished count increments if this is true.
applyHallMove :: Int -> RoomLens -> GraphState -> Move -> GraphState
applyHallMove rs roomLens gs NoMove = gs
applyHallMove rs roomLens gs m@(Move token h (rm, slot) _) =
let gs2 = case h of
H1 -> gs {hall1 = Nothing, lastMove = m, roomsFull = finishedCount}
H2 -> gs {hall2 = Nothing, lastMove = m, roomsFull = finishedCount}
H4 -> gs {hall4 = Nothing, lastMove = m, roomsFull = finishedCount}
H6 -> gs {hall6 = Nothing, lastMove = m, roomsFull = finishedCount}
H8 -> gs {hall8 = Nothing, lastMove = m, roomsFull = finishedCount}
H10 -> gs {hall10 = Nothing, lastMove = m, roomsFull = finishedCount}
H11 -> gs {hall11 = Nothing, lastMove = m, roomsFull = finishedCount}
in ...
where
finished = length (roomLens gs) == rs - 1
finishedCount = if finished then roomsFull gs + 1 else roomsFull gsNow we do the same concluding step as the room move, except this time we're adding the token to the room instead of removing it.
applyHallMove :: Int -> RoomLens -> GraphState -> Move -> GraphState
applyHallMove rs roomLens gs NoMove = gs
applyHallMove rs roomLens gs m@(Move token h (rm, slot) _) =
let gs2 = case h of
H1 -> gs {hall1 = Nothing, lastMove = m, roomsFull = finishedCount}
H2 -> gs {hall2 = Nothing, lastMove = m, roomsFull = finishedCount}
H4 -> gs {hall4 = Nothing, lastMove = m, roomsFull = finishedCount}
H6 -> gs {hall6 = Nothing, lastMove = m, roomsFull = finishedCount}
H8 -> gs {hall8 = Nothing, lastMove = m, roomsFull = finishedCount}
H10 -> gs {hall10 = Nothing, lastMove = m, roomsFull = finishedCount}
H11 -> gs {hall11 = Nothing, lastMove = m, roomsFull = finishedCount}
in case rm of
RA -> gs2 {roomA = A : roomA gs}
RB -> gs2 {roomB = B : roomB gs}
RC -> gs2 {roomC = C : roomC gs}
RD -> gs2 {roomD = D : roomD gs}
where
finished = length (roomLens gs) == rs - 1
finishedCount = if finished then roomsFull gs + 1 else roomsFull gsMaking the Initial State
That's the conclusion of the algorithm functions; now we just need some glue, such as the initial states and pulling it all together. For the first time with our Advent of Code problems, we don't actually need to parse an input file. We could go through this process, but the "hard" input is still basically the same size, so we can just define these initial states in code.
Let's recall that our basic case looks like this:
#############
#...........#
###B#C#B#D###
#A#D#C#A#
#########We'll translate it into an initial state as:
initialState1 :: GraphState
initialState1 = GraphState
NoMove 0 [B, A] [C, D] [B, C] [D, A]
Nothing Nothing Nothing Nothing Nothing Nothing NothingOur slightly harder version has the same structure, just with letters in more unusual places.
{-
#############
#...........#
###C#A#D#D###
#B#A#B#C#
#########
-}
initialState2 :: GraphState
initialState2 = GraphState
NoMove 0 [C, B] [A, A] [D, B] [D, C]
Nothing Nothing Nothing Nothing Nothing Nothing NothingNow for the "hard" part of the problem, we increase the room size to 4, and insert additional characters into each room. This is what those states look like.
initialState3 :: GraphState
initialState3 = GraphState
NoMove 0 [B, D, D, A] [C, C, B, D] [B, B, A, C] [D, A, C, A]
Nothing Nothing Nothing Nothing Nothing Nothing Nothing
initialState4 :: GraphState
initialState4 = GraphState
NoMove 0 [C, D, D, B] [A, C, B, A] [D, B, A, B] [D, A, C, C]
Nothing Nothing Nothing Nothing Nothing Nothing NothingSolving the Problem
Now we can "solve" each of the problems. Our solution code is essentially the same for each side. The "hard" part just passes 4 as the room size.
solveDay23Easy :: GraphState -> IO (Maybe Int)
solveDay23Easy gs = runStdoutLoggingT $ do
result <- dijkstraM (getNeighbors 2) getCost isComplete gs
case result of
Nothing -> return Nothing
Just (d, path) -> return $ Just d
solveDay23Hard :: GraphState -> IO (Maybe Int)
solveDay23Hard gs = runStdoutLoggingT $ do
result <- dijkstraM (getNeighbors 4) getCost isComplete gs
case result of
Nothing -> return Nothing
Just (d, path) -> return $ Just dAnd now our code is complete! We can run it and the total distance. It actually turns out to require less energy for the second case in each group:
First Size-2: 12521
Second Size-2: 10526
First Size-4: 44169
Second Size-4: 41284It's also possible, if we want, to print out the "path" we took by considering the moves in each state!
solveDay23Easy :: GraphState -> IO (Maybe Int)
solveDay23Easy gs = runStdoutLoggingT $ do
result <- dijkstraM (getNeighbors 2) getCost isComplete gs
case result of
Nothing -> return Nothing
Just (d, path) -> do
forM_ path $ \gs' -> logDebugN (pack . show $ lastMove gs')
return $ Just dHere's the path we take for this simple version! Remember that True moves come from the room into the hall, and False moves go from the hall back into the room.
[Debug] Move D H10 (RD,1) True
[Debug] Move A H2 (RD,2) True
[Debug] Move B H4 (RC,1) True
[Debug] Move C H6 (RB,1) True
[Debug] Move C H6 (RC,1) False
[Debug] Move D H8 (RB,2) True
[Debug] Move D H8 (RD,2) False
[Debug] Move D H10 (RD,1) False
[Debug] Move B H4 (RB,2) False
[Debug] Move B H4 (RA,1) True
[Debug] Move B H4 (RB,1) False
[Debug] Move A H2 (RA,1) FalseAs a final note, the scale of the search is fairly large but by no means intractable. My solution doesn't give an instant answer, but it returns within a minute or so.
Conclusion
That is all for our review of Advent of Code 2021! We'll have the video walkthrough later in the week. And then in a couple weeks, we'll be ready to start Advent of Code 2022, so stay tuned for that!
If you've enjoyed these tutorials, make sure to subscribe to our mailing list! We've got a big offer coming up next week that you won't want to miss!
Zoom/Enhance Video Walkthrough
Here’s our penultimate video walkthrough from Advent of Code 2021. Earlier this week was the in-depth code writeup for your perusal. The video is here on YouTube, and here’s the code on GitHub!
If you’re enjoying this content, make sure to subscribe to our monthly newsletter! Later this month you’ll also get access to some special offers on course content!
Zoom! Enhance!

Today we'll be tackling the Day 20 problem from Advent of Code 2021. This problem is a fun take on the Zoom and Enhance cliche from TV dramas where cops and spies can always seem to get unrealistic details from grainy camera footage by "enhancing" it. We'll have a binary image and we'll need to keep applying a decoding key to expand the image.
As always, you can see all the nitty gritty details of the code at once by going to the GitHub repository I've made for these problems. If you're enjoying these in-depth walkthroughs, make sure to subscribe so you can stay up to date with the latest news.
Problem Statement
Our problem input consists of a couple sections that have "binary" data, where the . character represents 0 and the # character represents 1.
..#.#..#####.#.#.#.###.##.....###.##.#..###.####..#####..#....#..#..##..##
#..######.###...####..#..#####..##..#.#####...##.#.#..#.##..#.#......#.###
.######.###.####...#.##.##..#..#..#####.....#.#....###..#.##......#.....#.
.#..#..##..#...##.######.####.####.#.#...#.......#..#.#.#...####.##.#.....
.#..#...##.#.##..#...##.#.##..###.#......#.#.......#.#.#.####.###.##...#..
...####.#..#..#.##.#....##..#.####....##...##..#...#......#.#.......#.....
..##..####..#...#.#.#...##..#.#..###..#####........#..####......#..#
#..#.
#....
##..#
..#..
..###The first part (which actually would appear all on one line) is a 512 character decoding key. Why length 512? Well 512 = 2^9, and we'll see in a second why the ninth power is significant.
The second part of the input is a 2D "image", represented in binary. Our goal is to "enhance" the image using the decoding key. How do we enhance it?
To get the new value at a coordinate (x, y), we have to consider the value at that coordinate together with all 8 of its neighbors.
# . . # .
#[. . .].
#[# . .]#
.[. # .].
. . # # #The brackets show every pixel that is involved in getting the new value at the "center" of our grid. The way we get the value is to line up these pixels in binary: ...#...#. = 000100010. Then we get the decimal value (34 in this case). This tells us new value comes from the 34th character in the decoder key, which is #. So this middle pixel will be "on" after the first expansion. Since each pixel expansion factors in 9 pixels, there are 2^9 = 512 possible values, hence the length of the decoding key.
All transformations happen simultaneously. What is noteworthy is that for "fringe" pixels we must account for the boundary outside the initial image. And in fact, our image then expands into this new region! The enhanced version of our first 5x5 image actually becomes size 7x7.
.##.##.
#..#.#.
##.#..#
####..#
.#..##.
..##..#
...#.#.For the easy part, we'll do this expansion twice. For the hard part, we'll do it 50 times. Our puzzle answer is the number of pixels that are lit in the final iteration.
Solution Approach
At first glance, this problem is pretty straightforward. It's another "state evolution" problem where we take the problem in an initial state and write a function to evolve that state to the next step. Evolving a single step involves looking at the individual pixels, and applying a fairly simple algorithm to get the resulting pixel.
The ever-expanding range of coordinates is a little tricky. But if we use a structure that allows "negative" indices (and Haskell makes this easy!), it's not too bad.
But there's one BIG nuance though with how the "infinite" image works. We still have to implicitly imagine that the enhancement algorithm is applying to all the other pixels in "infinite space". You would hope that, since all those pixels are surrounded by other "off" pixels, they remain "off".
However, my "hard" puzzle input got a decoding key with # in the 0 position, meaning that "off" pixels surrounded by other "off" pixels all turn on! Luckily, the decoder also has . in the final position, meaning that these pixels turn "off" again on the next step. However, we need to account for this on/off pattern of all these "outside pixels" since they'll affect the pixels on the fringe of our solution.
To that end, we'll need to keep track of the value of outer pixels throughout our algorithm - I'll refer to this as the "outside bit". This will impact every layer of the solution!
So with that to look forward to, let's start coding!
Utilities
As always, a few utilities will benefit us. From last week's look at binary numbers, we'll use a couple helpers like the Bit type and a binary-to-decimal conversion function.
data Bit = Zero | One
deriving (Eq, Ord)
bitsToDecimal64 :: [Bit] -> Word64Another very useful idea is turning a nested list into a hash map. This helps simplify parsing a lot. We saw this function in the Day 11 Octopus Problem.
hashMapFromNestedLists :: [[a]] -> HashMap Coord2 aAnother idea from Day 11 was getting all 8 neighbors of a 2D coordinate. Originally, we did this with (0,0) as a hard lower bound. But we can expand this idea so that the grid bounds of the function are taken as inputs. So getNeighbors8Flex takes two additional coordinate parameters to help provide those bounds for us.
getNeighbors8Flex :: Coord2 -> Coord2 -> Coord2 -> [Coord2]
getNeighbors8Flex (minRow, minCol) (maxRow, maxCol) (row, col) = catMaybes
[maybeUpLeft, maybeUp, maybeUpRight, maybeLeft, maybeRight, maybeDownLeft, maybeDown, maybeDownRight]
where
maybeUp = if row > minRow then Just (row - 1, col) else Nothing
maybeUpRight = if row > minRow && col < maxCol then Just (row - 1, col + 1) else Nothing
maybeRight = if col < maxCol then Just (row, col + 1) else Nothing
maybeDownRight = if row < maxRow && col < maxCol then Just (row + 1, col + 1) else Nothing
maybeDown = if row < maxRow then Just (row + 1, col) else Nothing
maybeDownLeft = if row < maxRow && col > minCol then Just (row + 1, col - 1) else Nothing
maybeLeft = if col > minCol then Just (row, col - 1) else Nothing
maybeUpLeft = if row > minRow && col > minCol then Just (row - 1, col - 1) else NothingOf particular note is the way we order the results. This ordering (top, then same row, then bottom), will allow us to easily decode our values for this problem.
Another detail for this problem is that we'll just want to use "no bounds" on the coordinates with the minimum and maximum integers as the bounds.
getNeighbors8Unbounded :: Coord2 -> [Coord2]
getNeighbors8Unbounded = getNeighbors8Flex (minBound, minBound) (maxBound, maxBound)Last but not least, we'll also rely on this old standby, the countWhere function, to quickly get the occurrence of certain values in a list.
countWhere :: (a -> Bool) -> [a] -> IntInputs
Like all Advent of Code problems, we'll start with parsing our input. We need to get everything into bits, but instead of 0 and 1 characters, we're dealing with the character . for off, and # for 1. So we start with a choice parser to get a single pixel.
parsePixel :: (MonadLogger m) => ParsecT Void Text m Bit
parsePixel = choice [char '.' >> return Zero, char '#' >> return One]Now we need a couple types to organize our values. The decoder map will tell us a particular bit for every index from 0-511. So we can use a hash map with Word64 as the key.
type DecoderMap = HashMap Word64 BitFurthermore, it's easy to see how we build this decoder from a list of bits with a simple zip:
buildDecoder :: [Bit] -> DecoderMap
buildDecoder input = HM.fromList (zip [0..] input)For the image though, we have 2D data. So let's using a hash map over Coord2 for our ImageMap type:
type ImageMap = HashMap Coord2 BitWe have enough tools to start writing our function now. We'll parse an initial series of pixels and build the decoder out of them, followed by a couple eol characters.
parseInput :: (MonadLogger m) => ParsecT Void Text m (DecoderMap, ImageMap)
parseInput = do
decoderMap <- buildDecoder <$> some parsePixel
eol >> eol
...Now we'll get the 2D image. We'll start by getting a nested list structure using the sepEndBy1 ... eol trick we've seen so many times already.
parse2DImage :: (MonadLogger m) => ParsecT Void Text m [[Bit]]
parse2DImage = sepEndBy1 (some parsePixel) eolNow to put it all together, we'll use our conversion function to get our map from the nested lists, and then we've got our two inputs: the DecoderMap and the initial ImageMap!
parseInput :: (MonadLogger m) => ParsecT Void Text m (DecoderMap, ImageMap)
parseInput = do
decoderMap <- buildDecoder <$> some parsePixel
eol >> eol
image <- hashMapFromNestedLists <$> parse2DImage
return (decoderMap, image)Processing One Pixel
In terms of writing out the algorithm, we'll try a "bottom up" approach this time. We'll start by solving the smallest problem we can think of, which is this: For a single pixel, how do we calculate its new value in one step of expansion?
There are multiple ways to approach this piece, but the way I chose was to imagine this as a folding function. We'll start a new "enhanced" image as an empty map, and we'll insert the new pixels one-by-one using this folding function. So each iteration modifies a single Coord2 key of an ImageMap. We can fit this into a "fold" pattern if the end of this function's signature looks like this:
-- At some point we have HM.insert coord bit newImage
f :: ImageMap -> Coord2 -> m ImageMap
f newImage coord = ...But we need some extra information in this function to solve the problem of which "bit" we're inserting. We'll need the original image of course, to find the pixels around this coordinate. We'll also need the decoding map once we convert these to a decimal index. Last of all, we need the "outside bit" discussed above in the solution approach. Here's a type signature to gather these together.
processPixel ::
(MonadLogger m) =>
DecoderMap ->
ImageMap ->
Bit ->
ImageMap -> Coord2 -> m ImageMap
processPixel decoderMap initialImage bounds outsideBit newImage pixel = ...Let's start with a helper function to get the original image's bit at a particular coordinate. Whenever we do a bit lookup outside our original image, its coordinates will not exist in the initialImage map. In this case we'll use the outside bit.
processPixel decoderMap initialImage outsideBit newImage pixel = do
...
where
getBit :: Coord2 -> Bit
getBit coord = fromMaybe outsideBit (initialImage HM.!? coord)Now we need to get all the neighboring coordinates of this pixel. We'll use our getNeighbors8Unbounded utility from above. We could restrict ourselves to the bounds of the original, augmented by 1, but there's no particular need. We get the bit at each location, and assert that we have indeed found all 8 neighbors.
processPixel decoderMap initialImage outsideBit newImage pixel = do
let allNeighbors = getNeighbors8Unbounded pixel
neighborBits = getBit <$> allNeighbors
if length allNeighbors /= 8
then error "Must have 8 neighbors!"
...
where
getBit = ...Now the "neighbors" function doesn't include the bit at the specific input pixel! So we have to split our neighbors and insert it into the middle like so:
processPixel decoderMap initialImage outsideBit newImage pixel = do
let allNeighbors = getNeighbors8Unbounded pixel
neighborBits = getBit <$> allNeighbors
if length allNeighbors /= 8
then error "Must have 8 neighbors!"
else do
let (first4, second4) = splitAt 4 neighborBits
finalBits = first4 ++ (getBit pixel : second4)
...
where
getBit = ...Now that we have a list of 9 bits, we can decode those bits (using bitsToDecimal64 from last time). This gives us the index to look up in our decoder, which we insert into the new image!
processPixel decoderMap initialImage outsideBit newImage pixel = do
let allNeighbors = getNeighbors8Unbounded pixel
neighborBits = getBit <$> allNeighbors
if length allNeighbors /= 8
then error "Must have 8 neighbors!"
else do
let (first4, second4) = splitAt 4 neighborBits
finalBits = first4 ++ (getBit pixel : second4)
indexToDecode = bitsToDecimal64 finalBits
bit = decoderMap HM.! indexToDecode
return $ HM.insert pixel bit newImage
where
getBit :: Coord2 -> Bit
getBit coord = fromMaybe outsideBit (initialImage HM.!? coord)Expanding the Image
Now that we can populate the value for a single pixel, let's step back one layer of the problem and determine how to expand the full image. As mentioned above, we ultimately want to use our function above like a fold. So we need enough arguments to reduce it to:
ImageMap -> Coord2 -> m ImageMapThen we can start with an empty image map, and loop through every coordinate. So let's make sure we include the decoder map, the original image, and the "outside bit" in our type signature to ensure we have all the processing arguments.
expandImage :: (MonadLogger m) => DecoderMap -> ImageMap -> Bit -> m ImageMap
expandImage decoderMap image outsideBit = ...Our chief task is to determine the coordinates to loop through. We can't just use the coordinates from the original image though. We have to expand by 1 in each direction so that the outside pixels can come into play. After adding 1, we use Data.Ix.range to interpolate all the coordinates in between our minimum and maximum.
expandImage decoderMap image outsideBit = ...
where
(minRow, minCol) = minimum (HM.keys image)
(maxRow, maxCol) = maximum (HM.keys image)
newBounds = ((minRow - 1, minCol - 1), (maxRow + 1, maxCol + 1))
allCoords = range newBoundsAnd now we have all the ingredients for our fold! We partially apply decoderMap, image, and outsideBit, and then use a fresh empty image and the coordinates.
expandImage decoderMap image outsideBit = foldM
(processPixel decoderMap image outsideBit)
HM.empty
allCoords
where
(minRow, minCol) = minimum (HM.keys image)
(maxRow, maxCol) = maximum (HM.keys image)
newBounds = ((minRow - 1, minCol - 1), (maxRow + 1, maxCol + 1))
allCoords = range newBoundsRunning the Expansion
Now that we can expand the image once, we just have to zoom out one more layer, and run the expansion a certain number of times. We'll write a recursive function that uses the decoder map, the initial image, and an integer argument for our current step count. This will return the total number of pixels that are lit in the final image.
runExpand :: (MonadLogger m) => DecoderMap -> ImageMap -> Int -> m IntThe base case occurs when we have 0 steps remaining. We'll just count the number of elements that have the One bit in our current image.
runExpand _ image 0 = return $ countWhere (== One) (HM.elems image)The only trick with the recursive case is that we have to determine the "outside bit". If the element corresponding to 0 in the decoder map is One, then all the outside bits will flip back and forth. So we need to check this bit, as well as the step count. For even step counts, we'll use Zero for the outside bits. And of course, if the decoder head is 0, then there's no flipping at all, so we always get Zero.
runExpand _ image 0 = return $ countWhere (== One) (HM.elems image)
runExpand decoderMap initialImage stepCount = do
...
where
outsideBit = if decoderMap HM.! 0 == Zero || even stepCount
then Zero
else OneNow we have all the arguments we need for our expandImage call! So let's get that new image and recurse using runExpand, with a reduced step count.
runExpand _ image 0 = return $ countWhere (== One) (HM.elems image)
runExpand decoderMap initialImage stepCount = do
finalImage <- expandImage decoderMap initialImage outsideBit
runExpand decoderMap finalImage (stepCount - 1)
where
outsideBit = if decoderMap HM.! 0 == Zero || even stepCount then Zero else OneSolving the Problem
Now we're well positioned to solve the problem. We'll parse the input into the decoder map and the first image with another old standby, parseFile. Then we'll run the expansion for 2 steps and return the number of lit pixels.
solveDay20Easy :: String -> IO (Maybe Int)
solveDay20Easy fp = runStdoutLoggingT $ do
(decoderMap, initialImage) <- parseFile parseInput fp
pixelsLit <- runExpand decoderMap initialImage 2
return $ Just pixelsLitThe hard part is virtually identical, just increasing the number of steps up to 50.
solveDay20Hard :: String -> IO (Maybe Int)
solveDay20Hard fp = runStdoutLoggingT $ do
(decoderMap, initialImage) <- parseFile parseInput fp
pixelsLit <- runExpand decoderMap initialImage 50
return $ Just pixelsLitAnd we're done!
Conclusion
Later this week we'll have the video walkthrough! If you want to see the complete code in action, you can take a look on GitHub.
If you subscribe to our monthly newsletter, you'll get all the latest news and offers from Monday Morning Haskell, as well as access to our subscriber resources!
Binary Packet Video Walkthrough
Here’s our 4th video walkthrough of some problems from last year’s Advent of Code. We had an in-depth code writeup back on Monday that you can check out. The video is here on YouTube, and you can also take a look at the code on GitHub!
If you’re enjoying this content, make sure to subscribe to our monthly newsletter! We’ll have some special offers coming out this month that you won’t want to miss!
Binary Packet Parsing
Today we're back with a new problem walkthrough, this time from Day 16 of last year's Advent of Code. In some sense, the parsing section for this problem is very easy - there's not much data to read from the file. In another sense, it's actually rather hard! This problem is about parsing a binary format, similar in some sense to how network packets work. It's a good exercise in handling a few different kinds of recursive cases.
As with the previous parts of this series, you can take a look at the code on GitHub here. This problem also has quite a few utilities, so you can observe those as well. This article is a deep-dive code walkthrough, so having the code handy to look at might be a good idea!
Problem Description
For this problem, we're decoding a binary packet. The packet is initially given as a hexadecimal string.
A0016C880162017C3686B18A3D4780But we'll turn it into binary and start working strictly with ones and zeros. However, the decoding process gets complicated because the packet is structured in a recursive way. But let's go over some of the rules.
Packet Header
Every packet has a six-bit header. The first three bits give a "version number" for the packet. The next three bits give a "type ID". That part's easy.
Then there are a series of rules about the rest of the information in the packet.
Literals
If the type ID is 4, the packet is a "literal". We then parse the remainder of the packet in 5-bit chunks. The first bit tells us if it is the last chunk of the packet (0 means yes, 1 means there are more chunks). The four other bits in the chunk are used to construct the binary number that forms the "value" of the literal. The more chunks, the higher the number can be.
Operator Sizes
Packets that aren't literals are operators. This means they contain a variable number of subpackets.
Operators have one bit (after the 6-bit header) giving a "length" type. A length type of "1" tells us that the following 11 bits give the number of subpackets. If the length bit is "0", then the next 15 bits give the length of all the subpackets in bits.
The Packet Structure
We'll see how these work out as we parse them. But with this structure in mind, one thing we can immediately do is come up with a recursive data type for a packet. I ended up calling this PacketNode since I thought of each as a node in a tree. It's pretty easy to see how to do this. We start with a base constructor for a Literal packet that only stores the version and the packet value. Then we just add an Operator constructor that will have a list of subpackets as well as a field for the operator type.
data PacketNode =
Literal Word8 Word64 |
Operator Word8 Word8 [PacketNode]
deriving (Show)Once we've parsed the packet, the "questions to answer" are, for the easy part, to take the sum of all the packet versions in our packet, and then to actually calculate the packet value recursively for the hard part. When we get to that part, we'll see how we use the operators to determine the value.
Solution Approach
The initial "parsing" part of this problem is actually quite easy. But we can observe that even after we have our binary values, it's still a parsing problem! We'll have an easy enough time answering the question once we've parsed our input into a PacketNode. So the core of the problem is parsing the ones and zeros into our PacketNode.
Since this is a parsing problem, we can actually use Megaparsec for the second part, instead of only for getting the input out of the file. Here's a possible signature for our core function:
-- More on this type later
data Bit = One | Zero
parsePacketNode :: (MonadLogger m) => ParsecT Void [Bit] m PacketNodeWhereas we normally use Text as the second type parameter to ParsecT, we can also use any list type, and the library will know what to do! With this function, we'll eventually be able to break our solution into its different parts. But first, we should start with some useful helpers for all our binary parsing.
Binary Utilities
Binary logic comes up fairly often in Advent of Code, and there are quite a few different utilities we would want to use with these ones and zeros. We start with a data type to represent a single bit. For maximum efficiency, we'd want to use a BitVector, but we aren't too worried about that. So we'll make a simple type with two constructors.
data Bit = Zero | One
deriving (Eq, Ord)
instance Show Bit where
show Zero = "0"
show One = "1"Our first order of business is turning a hexadecimal character into a list of bits. Hexadecimal numbers encapsulate 4 bits. So, for example, 0 should be [Zero, Zero, Zero, Zero], 1 should be [Zero, Zero, Zero, One], and F should be [One, One, One, One]. This is a simple pattern match, but we'll also have a failure case.
parseHexChar :: (MonadLogger m) => Char -> MaybeT m [Bit]
parseHexChar '0' = return [Zero, Zero, Zero, Zero]
parseHexChar '1' = return [Zero, Zero, Zero, One]
parseHexChar '2' = return [Zero, Zero, One, Zero]
parseHexChar '3' = return [Zero, Zero, One, One]
parseHexChar '4' = return [Zero, One, Zero, Zero]
parseHexChar '5' = return [Zero, One, Zero, One]
parseHexChar '6' = return [Zero, One, One, Zero]
parseHexChar '7' = return [Zero, One, One, One]
parseHexChar '8' = return [One, Zero, Zero, Zero]
parseHexChar '9' = return [One, Zero, Zero, One]
parseHexChar 'A' = return [One, Zero, One, Zero]
parseHexChar 'B' = return [One, Zero, One, One]
parseHexChar 'C' = return [One, One, Zero, Zero]
parseHexChar 'D' = return [One, One, Zero, One]
parseHexChar 'E' = return [One, One, One, Zero]
parseHexChar 'F' = return [One, One, One, One]
parseHexChar c = logErrorN ("Invalid Hex Char: " <> pack [c]) >> mzeroIf we wanted, we could also include lowercase, but this problem doesn't require it.
We also want to be able to turn a list of bits into a decimal number. We'll do this for a couple different sizes of numbers. For smaller numbers (8 bits or below), we might want to return a Word8. For larger numbers we can do Word64. Calculating the decimal number is a tail recursive process, where we track the accumulated sum and the current power of 2.
bitsToDecimal8 :: [Bit] -> Word8
bitsToDecimal8 bits = if length bits > 8
then error ("Too long! Use bitsToDecimal64! " ++ show bits)
else btd8 0 1 (reverse bits)
where
btd8 :: Word8 -> Word8 -> [Bit] -> Word8
btd8 accum _ [] = accum
btd8 accum mult (b : rest) = case b of
Zero -> btd8 accum (mult * 2) rest
One -> btd8 (accum + mult) (mult * 2) rest
bitsToDecimal64 :: [Bit] -> Word64
bitsToDecimal64 bits = if length bits > 64
then error ("Too long! Use bitsToDecimalInteger! " ++ (show $ bits))
else btd64 0 1 (reverse bits)
where
btd64 :: Word64 -> Word64 -> [Bit] -> Word64
btd64 accum _ [] = accum
btd64 accum mult (b : rest) = case b of
Zero -> btd64 accum (mult * 2) rest
One -> btd64 (accum + mult) (mult * 2) restLast of all, we should write a parser for reading a hexadecimal string from our file. This is easy, because Megaparsec already has a parser for a single hexadecimal character.
parseHexadecimal :: (MonadLogger m) => ParsecT Void Text m String
parseHexadecimal = some hexDigitCharBasic Bit Parsing
With all these utilities in place, we can get started with parsing our list of bits. As mentioned above, we want a function that generally looks like this:
parsePacketNode :: (MonadLogger m) => ParsecT Void [Bit] m PacketNodeHowever, we need one extra nuance. Because we have one layer that will parse several consecutive packets based on the number of bits parsed, we should also return this number as part of our function. In this way, we'll be able to determine if we're done with the subpackets of an operator packet.
parsePacketNode :: (MonadLogger m) => ParsecT Void [Bit] m (PacketNode, Word64)We'll also want a wrapper around this function so we can call it from a normal context with the list of bits as the input. This looks a lot like the existing utilities (e.g. for parsing a whole file). We use runParserT from Megaparsec and do a case-branch on the result.
parseBits :: (MonadLogger m) => [Bit] -> MaybeT m PacketNode
parseBits bits = do
result <- runParserT parsePacketNode "Utils.hs" bits
case result of
Left e -> logErrorN ("Failed to parse: " <> (pack . show $ e)) >> mzero
Right (packet, _) -> return packetWe ignore the "size" of the parsed packet in the primary case, but we'll use its result in the recursive calls to parsePacketNode!
Having done this, we can now start writing basic parser functions. To parse a single bit, we'll just wrap the anySingle combinator from Megaparsec.
parseBit :: ParsecT Void [Bit] m Bit
parseBit = anySingleIf we want to parse a certain number of bits, we'll want to use the monadic count combinator. Let's write a function that parses three bits and turns it into a Word8, since we'll need this for the packet version and type ID.
parse3Bit :: ParsecT Void [Bit] m Word8
parse3Bit = bitsToDecimal8 <$> count 3 parseBitWe can then immediately use this to start filling in our parsing function!
parsePacketNode :: (MonadLogger m) => ParsecT Void [Bit] m (PacketNode, Word64)
parsePacketNode = do
packetVersion <- parse3Bit
packetTypeId <- parse3Bit
...Then the rest of the function will depend upon the different cases we might parse.
Parsing a Literal
We can start with the "literal" case. This parses the "value" contained within the packet. We need to track the number of bits we parse so we can use this result in our parent function!
parseLiteral :: ParsecT Void [Bit] m (Word64, Word64)As explained above, we examine chunks 5 bits at a time, and we end the packet once we have a chunk that starts with 0. This is a "while" loop pattern, which suggests tail recursion as our solution!
We'll have two accumulator arguments. First, the series of bits that contribute to our literal value. Second, the number of bits we've parsed so far (which must include the signal bit).
parseLiteral :: ParsecT Void [Bit] m (Word64, Word64)
parseLiteral = parseLiteralTail [] 0
where
parseLiteralTail :: [Bit] -> Word64 -> ParsecT Void [Bit] m (Word64, Word64)
parseLiteralTail accumBits numBits = do
...First, we'll parse the leading bit, followed by the four bits in the chunk value. We append these to our previously accumulated bits, and add 5 to the number of bits parsed:
parseLiteral :: ParsecT Void [Bit] m (Word64, Word64)
parseLiteral = parseLiteralTail [] 0
where
parseLiteralTail :: [Bit] -> Word64 -> ParsecT Void [Bit] m (Word64, Word64)
parseLiteralTail accumBits numBits = do
leadingBit <- parseBit
nextBits <- count 4 parseBit
let accum' = accumBits ++ nextBits
let numBits' = numBits + 5
...If the leading bit is 0, we're done! We can return our value by converting our accumulated bits to decimal. Otherwise, we recurse with our new values.
parseLiteral :: ParsecT Void [Bit] m (Word64, Word64)
parseLiteral = parseLiteralTail [] 0
where
parseLiteralTail :: [Bit] -> Word64 -> ParsecT Void [Bit] m (Word64, Word64)
parseLiteralTail accumBits numBits = do
leadingBit <- parseBit
nextBits <- count 4 parseBit
let accum' = accumBits ++ nextBits
let numBits' = numBits + 5
if leadingBit == Zero
then return (bitsToDecimal64 accum', numBits')
else parseLiteralTail accum' numBits'Then it's very easy to incorporate this into our primary function. We check the type ID, and if it's "4" (for a literal), we call this function, and return with the Literal packet constructor.
parsePacketNode :: (MonadLogger m) => ParsecT Void [Bit] m (PacketNode, Word64)
parsePacketNode = do
packetVersion <- parse3Bit
packetTypeId <- parse3Bit
if packetTypeId == 4
then do
(literalValue, literalBits) <- parseLiteral
return (Literal packetVersion literalValue, literalBits + 6)
else
...Now we need to consider the "operator" cases and their subpackets.
Parsing from Number of Packets
We'll start with the simpler of these two cases, which is when we are parsing a specific number of subpackets. The first step, of course, is to parse the length type bit.
parsePacketNode :: (MonadLogger m) => ParsecT Void [Bit] m (PacketNode, Word64)
parsePacketNode = do
packetVersion <- parse3Bit
packetTypeId <- parse3Bit
if packetTypeId == 4
then do
(literalValue, literalBits) <- parseLiteral
return (Literal packetVersion literalValue, literalBits + 6)
else do
lengthTypeId <- parseBit
if lengthTypeId == One
then do
...First, we have to count out 11 bits and use that to determine the number of subpackets. Once we have this number, we just have to recursively call the parsePacketNode function the given number of times.
parsePacketNode :: (MonadLogger m) => ParsecT Void [Bit] m (PacketNode, Word64)
parsePacketNode = do
...
if packetTypeId == 4
then ...
else do
lengthTypeId <- parseBit
if lengthTypeId == One
then do
numberOfSubpackets <- bitsToDecimal64 <$> count 11 parseBit
subPacketsWithLengths <- replicateM (fromIntegral numberOfSubpackets) parsePacketNode
...We'll unzip these results to get our list of packets and the lengths. To get our final packet length, we take the sum of the sizes, but we can't forget to add the header bits and the length type bit (7 bits), and the bits from the number of subpackets (11).
parsePacketNode :: (MonadLogger m) => ParsecT Void [Bit] m (PacketNode, Word64)
parsePacketNode = do
...
if packetTypeId == 4
then ...
else do
lengthTypeId <- parseBit
if lengthTypeId == One
then do
numberOfSubpackets <- bitsToDecimal64 <$> count 11 parseBit
subPacketsWithLengths <- replicateM (fromIntegral numberOfSubpackets) parsePacketNode
let (subPackets, lengths) = unzip subPacketsWithLengths
return (Operator packetVersion packetTypeId subPackets, sum lengths + 7 + 11)
elseParsing from Number of Bits
Parsing based on the number of bits in all the subpackets is a little more complicated, because we have more state to track. As we loop through the different subpackets, we need to keep track of how many bits we still have to parse. So we'll make a separate helper function.
parseForPacketLength :: (MonadLogger m) => Int -> Word64 -> [PacketNode] -> ParsecT Void [Bit] m ([PacketNode], Word64)
parseForPacketLength remainingBits accumBits prevPackets = ...The base case comes when we have 0 bits remaining. Ideally, this occurs with exactly 0 bits. If it's a negative number, this is a problem. But if it's successful, we'll reverse the accumulated packets and return the number of bits we've accumulated.
parseForPacketLength :: (MonadLogger m) => Int -> Word64 -> [PacketNode] -> ParsecT Void [Bit] m ([PacketNode], Word64)
parseForPacketLength remainingBits accumBits prevPackets = if remainingBits <= 0
then do
if remainingBits < 0
then error "Failing"
else return (reverse prevPackets, accumBits)
else ...In the recursive case, we make one new call to parsePacketNode (the original function, not this helper). This gives us a new packet, and some more bits that we've parsed (this is why we've been tracking that number the whole time). So we can subtract the size from the remaining bits, and add it to the accumulated bits. And then we'll make the actual recursive call to this helper function.
parseForPacketLength :: (MonadLogger m) => Int -> Word64 -> [PacketNode] -> ParsecT Void [Bit] m ([PacketNode], Word64)
parseForPacketLength remainingBits accumBits prevPackets = if remainingBits <= 0
then do
if remainingBits < 0
then error "Failing"
else return (reverse prevPackets, accumBits)
else do
(newPacket, size) <- parsePacketNode
parseForPacketLength (remainingBits - fromIntegral size) (accumBits + fromIntegral size) (newPacket : prevPackets)And that's all! All our different pieces fit together now and we're able to parse our packet!
Solving the Problems
Now that we've parsed the packet into our structure, the rest of the problem is actually quite easy and fun! We've created a straightforward recursive structure, and so we can loop through it in a straightforward recursive way. We'll just always use the Literal as the base case, and then loop through the list of packets for the base case.
Let's start with summing the packet versions. This will return a Word64 since we could be adding a lot of package versions. With a Literal package, we just immediately return the version.
sumPacketVersions :: PacketNode -> Word64
sumPacketVersions (Literal v _) = fromIntegral v
...Then with operator packets, we just map over the sub-packets, take the sum of their versions, and then add the original packet's version.
sumPacketVersions :: PacketNode -> Word64
sumPacketVersions (Literal v _) = fromIntegral v
sumPacketVersions (Operator v _ packets) = fromIntegral v +
sum (map sumPacketVersions packets)Now, for calculating the final packet value, we again start with the Literal case, since we'll just return its value. Note that we'll do this monadically, since we'll have some failure conditions in the later parts.
calculatePacketValue :: MonadLogger m => PacketNode -> MaybeT m Word64
calculatePacketValue (Literal _ x) = return xNow, for the first time in the problem, we actually have to care what the operators mean! Here's a summary of the first few operators:
0 = Sum of all subpackets
1 = Product of all subpackets
2 = Minimum of all subpackets
3 = Maximum of all subpacketsThere are three other operators following the same basic pattern. They expect exactly two subpackets and perform a binary, boolean operator. If it is true, the value is 1. If the operation is false, the packet value is 0.
5 = Greater than operator (<)
6 = Less than operator (>)
7 = Equals operator (==)For the first set of operations, we can recursively calculate the value of the sub-packets, and take the appropriate aggregate function over the list.
calculatePacketValue :: MonadLogger m => PacketNode -> MaybeT m Word64
calculatePacketValue (Literal _ x) = return x
calculatePacketValue (Operator _ 0 packets) = sum <$> mapM calculatePacketValue packets
calculatePacketValue (Operator _ 1 packets) = product <$> mapM calculatePacketValue packets
calculatePacketValue (Operator _ 2 packets) = minimum <$> mapM calculatePacketValue packets
calculatePacketValue (Operator _ 3 packets) = maximum <$> mapM calculatePacketValue packets
...For the binary operations, we first have to verify that there are only two packets.
calculatePacketValue :: MonadLogger m => PacketNode -> MaybeT m Word64
...
calculatePacketValue (Operator _ 5 packets) = do
if length packets /= 2
then logErrorN "> operator '5' must have two packets!" >> mzero
else ...Then we just de-structure the packets, calculate each value, compare them, and then return the appropriate value.
calculatePacketValue :: MonadLogger m => PacketNode -> MaybeT m Word64
...
calculatePacketValue (Operator _ 5 packets) = do
if length packets /= 2
then logErrorN "> operator '5' must have two packets!" >> mzero
else do
let [p1, p2] = packets
v1 <- calculatePacketValue p1
v2 <- calculatePacketValue p2
return (if v1 > v2 then 1 else 0)
calculatePacketValue (Operator _ 6 packets) = do
if length packets /= 2
then logErrorN "< operator '6' must have two packets!" >> mzero
else do
let [p1, p2] = packets
v1 <- calculatePacketValue p1
v2 <- calculatePacketValue p2
return (if v1 < v2 then 1 else 0)
calculatePacketValue (Operator _ 7 packets) = do
if length packets /= 2
then logErrorN "== operator '7' must have two packets!" >> mzero
else do
let [p1, p2] = packets
v1 <- calculatePacketValue p1
v2 <- calculatePacketValue p2
return (if v1 == v2 then 1 else 0)
calculatePacketValue p = do
logErrorN ("Invalid packet! " <> (pack . show $ p))
mzeroConcluding Code
To tie everything together, we just follow the steps.
- Parse the hexadecimal from the file
- Transform the hexadecimal string into a list of bits
- Parse the packet
- Answer the question
For the first part, we use sumPacketVersions on the resulting packet.
solveDay16Easy :: String -> IO (Maybe Int)
solveDay16Easy fp = runStdoutLoggingT $ do
hexLine <- parseFile parseHexadecimal fp
result <- runMaybeT $ do
bitLine <- concatMapM parseHexChar hexLine
packet <- parseBits bitLine
return $ sumPacketVersions packet
return (fromIntegral <$> result)And the "hard" solution is the same, except we use calculatePacketValue instead.
solveDay16Hard :: String -> IO (Maybe Int)
solveDay16Hard fp = runStdoutLoggingT $ do
hexLine <- parseFile parseHexadecimal fp
result <- runMaybeT $ do
bitLine <- concatMapM parseHexChar hexLine
packet <- parseBits bitLine
calculatePacketValue packet
return (fromIntegral <$> result)And we're done!
Conclusion
That's all for this solution! As always, you can take a look at the code on GitHub. Later this week I'll have the video walkthrough as well. To keep up with all the latest news, make sure to subscribe to our monthly newsletter! Subscribing will give you access to our subscriber resources, like our Beginners Checklist and our Production Checklist.
Polymer Expansion Video Walkthrough
Earlier this week I did a write-up of the Day 14 Problem from Advent of Code 2021. Today, I’m releasing a video walkthrough that you can watch here on YouTube!
If you’re enjoying this content, make sure to subscribe to our monthly newsletter! This will give you access to our subscriber resources!
Polymer Expansion

Today we're back with another Advent of Code walkthrough. We're doing the problem from Day 14 of last year. Here are a couple previous walkthroughs:
If you want to see the code for today, you can find it here on GitHub!
If you're enjoying these problem overviews, make sure to subscribe to our monthly newsletter!
Problem Statement
The subject of today's problem is "polymer expansion". What this means in programming terms is that we'll be taking a string and inserting new characters into it based on side-by-side pairs.
The puzzle input looks like this:
NNCB
NN -> C
NC -> B
CB -> H
...The top line of the input is our "starter string". It's our base for expansion. The lines that follow are codes that explain how to expand each pair of characters.
So in our original string of four characters (NNCB), there are three pairs: NN, NC, and CB. With the exception of the start and end characters, each character appears in two different pairs. So for each pair, we find the corresponding "insertion character" and construct a new string where all the insertion characters come between their parent pairs. The first pair gives us a C, the second pair gives us a new B, and the third pair gets us a new H.
So our string for the second step becomes: NCNBCHB. We'll then repeat the expansion a certain number of times.
For the first part, we'll run 10 steps of the expansion algorithm. For the second part, we'll do 40 steps. Each time, our final answer comes from taking the number of occurrences of the most common letter in the final string, and subtracting the occurrences of the least common letter.
Utilities
The main utility we'll end up using for this problem is an occurrence map. I decided to make this general idea for counting the number of occurrences of some item, since it's such a common pattern in these puzzles. The most generic alias we could have is a map where the key and value are parameterized, though the expectation is that i is an Integral type:
type OccMapI a i = Map a iThe most common usage is counting items up from 0. Since this is an unsigned, non-negative number, we would use Word.
type OccMap a = Map a WordHowever, for today's problem, we're gonna be dealing with big numbers! So just to be safe, we'll use the unbounded Integer type, and make a separate type definition for that.
type OccMapBig a = Map a IntegerWe can make a couple useful helper functions for this occurrence map. First, we can add a certain number value to a key.
addKey :: (Ord a, Integral i) => OccMapI a i -> a -> i -> OccMapI a i
addKey prevMap key count = case M.lookup key prevMap of
Nothing -> M.insert key count prevMap
Just x -> M.insert key (x + count) prevMapWe can add a specialization of this for "incrementing" a key, adding 1 to its value. We won't use this for today's solution, but it helps in a lot of cases.
incKey :: (Ord a, Integral i) => OccMapI a i -> a -> OccMapI a i
incKey prevMap key = addKey prevMap key 1Now with our utilities out of the way, let's start parsing our input!
Parsing the Input
First off, let's define the result types of our parsing process. The starter string comes on the first line, so that's a separate String. But then we need to create a mapping between character pairs and the resulting character. We'll eventually want these in a HashMap, so let's make a type alias for that.
type PairMap = HashMap (Char, Char) CharNow for parsing, we need to parse the start string, an empty line, and then each line of the code mapping.
Since most of the input is in the code mapping lines, let's do that first. Each line consists of parsing three characters, just separated by the arrow. This is very straightforward with Megaparsec.
parsePairCode :: (MonadLogger m) => ParsecT Void Text m (Char, Char, Char)
parsePairCode = do
input1 <- letterChar
input2 <- letterChar
string " -> "
output <- letterChar
return (input1, input2, output)Now let's make a function to combine these character tuples into the map. This is a nice quick fold:
buildPairMap :: [(Char, Char, Char)] -> HashMap (Char, Char) Char
buildPairMap = foldl (\prevMap (c1, c2, c3) -> HM.insert (c1, c2) c3 prevMap) HM.emptyThe rest of our parsing function then parses the starter string and a couple newline characters before we get our pair codes.
parseInput :: (MonadLogger m) => ParsecT Void Text m (String, PairMap)
parseInput = do
starterCode <- some letterChar
eol >> eol
pairCodes <- sepEndBy1 parsePairCode eol
return (starterCode, buildPairMap pairCodes)Then it will be easy enough to use our parseFile function from previous days. Now let's figure out our solution approach.
A Naive Approach
Now at first, the polymer expansion seems like a fairly simple problem. The root of the issue is that we have to write a function to run one step of the expansion. In principle, this isn't a hard function. We loop through the original string, two letters at a time, and gradually construct the new string for the next step.
One way to handle this would be with a tail recursive helper function. We could accumulate the new string (in reverse) through an accumulator argument.
runExpand :: (MonadLogger m)
=> PairMap
-> String -- Accumulator
-> String -- Remaining String
-> m StringThe "base case" of this function is when we have only one character left. In this case, we append it to the accumulator and reverse it all.
runExpand :: (MonadLogger m) => PairMap -> String -> String -> m String
runExpand pairMap accum [lastChar] = return $ reverse (lastChar : accum)For the recursive case, we imagine we have at least two characters remaining. We'll look these characters up in our map. Then we'll append the first character and the new character to our accumulator, and then recurse on the remainder (including the second character).
runExpand :: (MonadLogger m) => PairMap -> String -> String -> m String
runExpand _ accum [lastChar] = return $ reverse (lastChar : accum)
runExpand pairMap accum (firstChar: secondChar : rest) = do
let insertChar = pairMap HM.! (nextChar, secondChar)
runExpand pairMap (insertChar : firstChar : accum) (secondChar : rest)There are some extra edge cases we could handle here, but this isn't going to be how we solve the problem. The approach works...in theory. In practice though, it only works for a small number of steps. Why? Well the problem description gives a hint: This polymer grows quickly. In fact, with each step, our string essentially doubles in size - exponential growth!
This sort of solution is good enough for the first part, running only 10 steps. However, as the string gets bigger and bigger, we'll run out of memory! So we need something more efficient.
A Better Approach
The key insight here is that we don't actually care about the order of the letters in the string at any given time. All we really need to think about is the number of each kind of pair that is present. How does this work?
Well recall some of our basic code pairs from the top:
NN -> C
NC -> B
CB -> H
BN -> BWith the starter string like NNCB, we have one NN pair, an NC pair, and CB pair. In the next step, the NN pair generates two new pairs. Because a C is inserted between the N, we lose the NN pair but gain a NC pair and a CN pair. So after expansion the number of resulting NC pairs is 1, and the number of CN pairs is 1.
However, this is true of every NN pair within our string! Suppose we instead start off this with:
NNCBNN
Now there are two NN pairs, meaning the resulting string will have two NC pairs and two CN pairs, as you can see by taking a closer look at the result: NCNBCHBBNCN.
So instead of keeping the complete string in memory, all we need to do is use the "occurrence map" utility to store the number of each pair for our current state. So we'll keep folding over an object of type OccMapBig (Char, Char).
The first step of our solution then is to construct our initial mapping from the starter code. We can do this by folding through the starter string in a similar way to the example code in the naive solution. We one or zero characters are left in our "remainder", that's a base case and we can return the map.
-- Same signature as naive approach
expandPolymerLong :: (MonadLogger m) => Int -> String -> PairMap -> m (Maybe Integer)
expandPolymerLong numSteps starterCode pairMap = do
let starterMap = buildInitialMap M.empty starterCode
...
where
buildInitialMap :: OccMapBig (Char, Char) -> String -> OccMapBig (Char, Char)
buildInitialMap prevMap "" = prevMap
buildInitialMap prevMap [_] = prevMap
...Now for the recursive case, we have at least two characters remaining, so we'll just increment the value for the key formed by these characters!
-- Same signature as naive approach
expandPolymerLong :: (MonadLogger m) => Int -> String -> PairMap -> m (Maybe Integer)
expandPolymerLong numSteps starterCode pairMap = do
let starterMap = buildInitialMap M.empty starterCode
...
where
buildInitialMap :: OccMapBig (Char, Char) -> String -> OccMapBig (Char, Char)
buildInitialMap prevMap "" = prevMap
buildInitialMap prevMap [_] = prevMap
buildInitialMap prevMap (firstChar : secondChar : rest) = buildInitialMap (incKey prevMap (firstChar, secondChar)) (secondChar : rest)The key point, of course, is how to expand our map each step, so let's do this next!
A New Expansion
To run a single step in our naive solution, we could use a tail-recursive helper to gradually build up the new string (the "accumulator") from the old string (the "remainder" or "rest"). So our type signature looked like this:
runExpand :: (MonadLogger m)
=> PairMap
-> String -- Accumulator
-> String -- Remainder
-> m StringFor our new expansion step, we're instead taking one occurrence map and transforming it into a new occurrence map. For convenience, we'll include an integer argument keeping track of which step we're on, but we won't need to use it in the function. We'll do all this within expandPolymerLong so that we have access to the PairMap argument.
expandPolymerLong :: (MonadLogger m) => Int -> String -> PairMap -> m (Maybe Integer)
expandPolymerLong numSteps starterCode pairMap = do
...
where
runStep ::(MonadLogger m) => OccMapBig (Char, Char) -> Int -> m (OccMapBig (Char, Char))
runStep = ...The runStep function has a simple idea behind it though. We gradually reconstruct our occurrence map by folding through the pairs in the previous map. We'll make a new function runExpand to act as the folding function.
expandPolymerLong :: (MonadLogger m) => Int -> String -> PairMap -> m (Maybe Integer)
expandPolymerLong numSteps starterCode pairMap = do
...
where
runStep ::(MonadLogger m) => OccMapBig (Char, Char) -> Int -> m (OccMapBig (Char, Char))
runStep prevMap _ = foldM runExpand M.empty (M.toList prevMap)
runExpand :: (MonadLogger m) => OccMapBig (Char, Char) -> ((Char, Char), Integer) -> m (OccMapBig (Char, Char))
runExpand = ...For this function, we begin by looking up the two-character code in our map. If for whatever reason it doesn't exist, we'll move on, but it's worth logging an error message since this isn't supposed to happen.
runExpand :: (MonadLogger m) => OccMapBig (Char, Char) -> ((Char, Char), Integer) -> m (OccMapBig (Char, Char))
runExpand prevMap (code@(c1, c2), count) = case HM.lookup code pairMap of
Nothing -> logErrorN ("Missing Code: " <> pack [c1, c2]) >> return prevMap
Just newChar -> ...Now once we've found the new character, we'll create our first new pair and our second new pair by inserting the new character with our previous characters.
runExpand :: (MonadLogger m) => OccMapBig (Char, Char) -> ((Char, Char), Integer) -> m (OccMapBig (Char, Char))
runExpand prevMap (code@(c1, c2), count) = case HM.lookup code pairMap of
Nothing -> logErrorN ("Missing Code: " <> pack [c1, c2]) >> return prevMap
Just newChar -> do
let first = (c1, newChar)
second = (newChar, c2)
...And to wrap things up, we add the new count value for each of our new keys to the existing map! This is done with nested calls to addKey on our occurrence map.
runExpand :: (MonadLogger m) => OccMapBig (Char, Char) -> ((Char, Char), Integer) -> m (OccMapBig (Char, Char))
runExpand prevMap (code@(c1, c2), count) = case HM.lookup code pairMap of
Nothing -> logErrorN ("Missing Code: " <> pack [c1, c2]) >> return prevMap
Just newChar -> do
let first = (c1, newChar)
second = (newChar, c2)
return $ addKey (addKey prevMap first count) second countRounding Up
Now we have our last task: finding the counts of the characters in the final string, and subtracting the minimum from the maximum. This requires us to first disassemble our mapping of pair counts into a mapping of individual character counts. This is another fold step. But just like before, we use nested calls to addKey on an occurrence map! See how countChars works below:
expandPolymerLong :: (MonadLogger m) => Int -> String -> PairMap -> m (Maybe Integer)
expandPolymerLong numSteps starterCode pairMap = do
let starterMap = buildInitialMap M.empty starterCode
finalOccMap <- foldM runStep starterMap [1..numSteps]
let finalCharCountMap = foldl countChars M.empty (M.toList finalOccMap)
...
where
countChars :: OccMapBig Char -> ((Char, Char), Integer) -> OccMapBig Char
countChars prevMap ((c1, c2), count) = addKey (addKey prevMap c1 count) c2 countSo we have a count of the characters in our final string...sort of. Recall that we added characters for each pair. Thus the number we're getting is basically doubled! So we want to divide each value by 2, with the exception of the first and last characters in the string. If these are the same, we have an edge case. We divide the number by 2 and then add an extra one. Otherwise, if a character has an odd value, it must be on the end, so we divide by two and round up. We sum up this logic with the quotRoundUp function, which we apply over our finalCharCountMap.
expandPolymerLong :: (MonadLogger m) => Int -> String -> PairMap -> m (Maybe Integer) expandPolymerLong numSteps starterCode pairMap = do let starterMap = buildInitialMap M.empty starterCode finalOccMap <- foldM runStep starterMap [1..numSteps] let finalCharCountMap = foldl countChars M.empty (M.toList finalOccMap) let finalCounts = map quotRoundUp (M.toList finalCharCountMap) ... where quotRoundUp :: (Char, Integer) -> Integer quotRoundUp (c, i) = if even i then quot i 2 + if head starterCode == c && last starterCode == c then 1 else 0 else quot i 2 + 1
And finally, we consider the list of outcomes and take the maximum minus the minimum!
```haskell
expandPolymerLong :: (MonadLogger m) => Int -> String -> PairMap -> m (Maybe Integer)
expandPolymerLong numSteps starterCode pairMap = do
let starterMap = buildInitialMap M.empty starterCode
finalOccMap <- foldM runStep starterMap [1..numSteps]
let finalCharCountMap = foldl countChars M.empty (M.toList finalOccMap)
let finalCounts = map quotRoundUp (M.toList finalCharCountMap)
if null finalCounts
then logErrorN "Final Occurrence Map is empty!" >> return Nothing
else return $ Just $ fromIntegral (maximum finalCounts - minimum finalCounts)
where
buildInitialMap = ...
runStep = ...
runExpand = ...
countChars = ...
quotRoundUp = ...Last of all, we combine input parsing with solving the problem. Our "easy" and "hard" solutions look the same, just with different numbers of steps.
solveDay14Easy :: String -> IO (Maybe Integer)
solveDay14Easy fp = runStdoutLoggingT $ do
(starterCode, pairCodes) <- parseFile parseInput fp
expandPolymerLong 10 starterCode pairCodes
solveDay14Hard :: String -> IO (Maybe Integer)
solveDay14Hard fp = runStdoutLoggingT $ do
(starterCode, pairCodes) <- parseFile parseInput fp
expandPolymerLong 40 starterCode pairCodesConclusion
Hopefully that solution makes sense to you! In case I left anything out of my solution, you can peruse the code on GitHub. Later this week, we'll have a video walkthrough of this solution!
If you're enjoying this content, make sure to subscribe to our monthly newsletter, which will also give you access to our Subscriber Resources!
Dijkstra Video Walkthrough
Today I’m taking a really quick break from Advent of Code videos to do a video walkthrough of Dijkstra’s algorithm! I did several written walkthroughs of this algorithm a couple months ago:
However, I never did a video walkthrough on my YouTube channel, and a viewer specifically requested one, so here it is today!
If you enjoyed that video, make sure to subscribe to our monthly newsletter so you can stay up to date on our latest content! This will also give you access to our subscriber resources!
Octopus Energy - Video Walkthrough
Here’s another Video walkthrough, which you can find here on YouTube. This is for the Day 11 problem. You can find a detailed written walkthrough here. The code is also available on GitHub.
There will be one non-Advent-of-Code video later this week, and then next week we’ll be back with more problem solving walkthroughs!
Seven Segment Display - Video Walkthrough
As promised, today I’m back on YouTube, releasing a video walkthrough of my solution to the Seven Segment Display problem that we went over last week in this detailed blog post.
Next week I’ll be following up with another video walkthrough, this time for Day 11 that we covered earlier this week! Make sure to subscribe if you’re enjoying this content!
Flashing Octopuses and BFS
Today we continue our new series on Advent of Code solutions from 2021. Last time we solved the seven-segment logic puzzle. Today, we'll look at the Day 11 problem which focuses a bit more on traditional coding structures and algorithms.
This will be another in-depth coding write-up. For the next week or so after this I'll switch to doing video reviews so you can compare the styles. I haven't been too exhaustive with listing imports in these examples though, so if you're curious about those you can take a look at the full solution here on GitHub. So now, let's get started!
Problem Statement
For this problem, we're dealing with a set of Octopuses, (Advent of Code had an aquatic theme last year) and these octopuses apparently have an "energy level" and eventually "flash" when they reach their maximum energy level. They sit nicely in a 2D grid for us, and the puzzle input is just a grid of single-digit integers for their initial "energy level". Here's an example.
5483143223
2745854711
5264556173
6141336146
6357385478
4167524645
2176841721
6882881134
4846848554
5283751526Now, as time goes by, their energy levels increase. With each step, all energy levels go up by one. So after a single step, the energy grid looks like this:
6594254334
3856965822
6375667284
7252447257
7468496589
5278635756
3287952832
7993992245
5957959665
6394862637However, when an octopus reaches level 10, it flashes. This has two results for the next step. First, its own energy level always reverts to 0. Second, it increments the energy level of all neighbors as well. This, of course, can make things more complicated, because we can end up with a cascading series of flashes. Even an octopus that has a very low energy level at the start of a step can end up flashing. Here's an example.
Start:
11111
19891
18181
19891
11111
End:
34543
40004
50005
40004
34543The 1 in the center still ends up flashing. It has four neighbors as 9 which all flash. The surrounding 8's then flash because each has two 9 neighbors. As a result, the 1 has 8 neighbors flashing. Combining with its own increment, it becomes as 10, so it also flashes.
The good news is that all flashing octopuses revert to 0. They don't start counting again from other adjacent flashes so we can't get an infinite loop of flashing and we don't have to worry about the "order" of flashing.
For the first part of the problem, we have to find the total number of flashes after a certain number of steps. For the second part, we have to find the first step when all of the octopuses flash.
Solution Approach
There's nothing too difficult about the solution approach here. Incrementing the grid and finding the initial flashes are easy problems. The only tricky part is cascading the flashes. For this, we need a Breadth-First-Search where each item in the queue is a flash to resolve. As long as we're careful in our accounting and in the update step, we should be able to answer the questions fairly easily.
Utilities
As with last time, we'll start the coding portion with a few utilities that will (hopefully) end up being useful for other problems. The first of these is a simple one. We'll use a type synonym Coord2 to represent a 2D integer coordinate.
type Coord2 = (Int, Int)Next, we'll want another general parsing function. Last time, we covered parseLinesFromFile, which took a general parser and applied it to every line of an input file. But we also might want to incorporate the "line-by-line" behavior into our general parser, so we'll add a function to parse the whole file given a single ParsecT expression. The structure is much the same, it just does even less work than our prior example.
parseFile :: (MonadIO m) => ParsecT Void Text m a -> FilePath -> m a
parseFile parser filepath = do
input <- pack <$> liftIO (readFile filepath)
result <- runParserT parser "Utils.hs" input
case result of
Left e -> error $ "Failed to parse: " ++ show e
Right x -> return xLast of all, this problem deals with 2D grids and spreading out the "effect" of one square over all eight of its neighbors. So let's write a function to get all the adjacent coordinates of a tile. We'll call this neighbors8, and it will be very similar to a function getting neighbors in 4 directions that I used in this Dijkstra's algorithm implementation.
getNeighbors8 :: HashMap Coord2 a -> Coord2 -> [Coord2]
getNeighbors8 grid (row, col) = catMaybes
[maybeUp, maybeUpRight, maybeRight, maybeDownRight, maybeDown, maybeDownLeft, maybeLeft, maybeUpLeft]
where
(maxRow, maxCol) = maximum $ HM.keys grid
maybeUp = if row > 0 then Just (row - 1, col) else Nothing
maybeUpRight = if row > 0 && col < maxCol then Just (row - 1, col + 1) else Nothing
maybeRight = if col < maxCol then Just (row, col + 1) else Nothing
maybeDownRight = if row < maxRow && col < maxCol then Just (row + 1, col + 1) else Nothing
maybeDown = if row < maxRow then Just (row + 1, col) else Nothing
maybeDownLeft = if row < maxRow && col > 0 then Just (row + 1, col - 1) else Nothing
maybeLeft = if col > 0 then Just (row, col - 1) else Nothing
maybeUpLeft = if row > 0 && col > 0 then Just (row - 1, col - 1) else NothingThis function could also apply to an Array instead of a Hash Map. In fact, it might be even more appropriate there. But below we'll get into the reasons for using a Hash Map.
Parsing the Input
Now, let's get to the first step of the problem itself, which is to parse the input. In this case, the input is simply a 2D array of single-digit integers, so this is a fairly straightforward process. In fact, I figured this whole function could be re-used as well, so it could also be considered a utility.
The first step is to parse a line of integers. Since there are no spaces and no separators, this is very simple using some.
import Data.Char (digitToInt)
import Text.Megaparsec (some)
parseDigitLine :: ParsecT Void Text m [Int]
parseDigitLine = fmap digitToInt <$> some digitCharNow getting a repeated set of these "integer lists" over a series of lines uses the same trick we saw last time. We use sepEndBy1 combined with the eol parser for end-of-line.
parse2DDigits :: (Monad m) => ParsecT Void Text m [[Int]]
parse2DDigits = sepEndBy1 parseDigitLine eolHowever, we want to go one step further. A list-of-lists-of-ints is a cumbersome data structure. We can't really update it efficiently. Nor, in fact, can we even access 2D indices quickly. There are two good structures for us to use, depending on the problem. We can either use a 2D array, or a HashMap where the keys are 2D coordinates.
Because we'll be updating the structure itself, we want a Hash Map in this case. Haskell's Array structure has no good way to update its values without a full copy. If the structure were read only though, Array would be the better choice. For our current problem, the mutable array pattern would also be an option. But for now I'll keep things simpler.
So we need a function to convert nested integer lists into a Hash Map with coordinates. The first step in this process is to match each list of integers with a row number, and each integer within the list with its column number. Infinite lists, ranges and zip are excellent tools here!
hashMapFromNestedLists :: [[Int]] -> HashMap Coord2 Int
hashMapFromNestedLists inputs = ...
where
x = zip [0,1..] (map (zip [0,1..]) inputs)Now in most languages, we would use a nested for-loop. The outer structure would cover the rows, the inner structure would cover the columns. In Haskell, we'll instead do a 2-level fold. The outer layer (the function f) will cover the rows. The inner layer (function g) will cover the columns. Each step updates the Hash Map appropriately.
hashMapFromNestedLists :: [[Int]] -> HashMap Coord2 Int
hashMapFromNestedLists inputs = foldl f HM.empty x
where
x = zip [0,1..] (map (zip [0,1..]) inputs)
f :: HashMap Coord2 Int -> (Int, [(Int, Int)]) -> HashMap Coord2 Int
f prevMap (row, pairs) = foldl (g row) prevMap pairs
g :: Int -> HashMap Coord2 Int -> Coord2 -> HashMap Coord2 Int
g row prevMap (col, val) = HM.insert (row, col) val prevMapAnd now we can pull it all together and parse our input!
solveDay11Easy :: String -> IO (Maybe Int)
solveDay11Easy fp = do
initialState <- parseFile parse2DDigitHashMap fp
...
solveDay11Hard :: String -> IO (Maybe Int)
solveDay11Hard fp = do
initialState <- parseFile parse2DDigitHashMap fp
...Basic Step Running
Now let's get to the core of the algorithm. The function we really need to get right here is a function to update a single step of the process. This will take our grid as an input and produce the new grid as an output, as well as some extra information. Let's start by making another type synonym for OGrid as the "Octopus grid".
type OGrid = HashMap Coord2 IntNow a simple version of this function would have a type signature like this:
runStep :: (MonadLogger m) => OGrid -> m OGrid(As mentioned last time, I'm defaulting to using MonadLogger for most implementation details).
However, we'll include two extra outputs for this function. First, we want an Int for the number of flashes that occurred on this step. This will help us with the first part of the problem, where we are summing the number of flashes given a certain number of steps.
Second, we want a Bool indicating that all of them have flashed. This is easy to derive from the number of flashes and will be our terminal condition flag for the second part of the problem.
runStep :: (MonadLogger m) => OGrid -> m (OGrid, Int, Bool)Now the first thing we can do while stepping is to increment everything. Once we've done that, it is easy to pick out the coordinates that ought be our "initial flashes" - all the items where the value is at least 10.
runStep :: (MonadLogger m) => OGrid -> m (OGrid, Int, Bool)
runStep = ...
where
-- Start by incrementing everything
incrementedGrid = (+1) <$> inputGrid
initialFlashes = fst <$> filter (\(_, x) -> x >= 10) (HM.toList incrementedGrid)Now what do we do with our initial flashes to propagate them? Let's defer this to a helper function, processFlashes. This will be where we perform the BFS step recursively. Using BFS requires a queue and a visited set, so we'll want these as arguments to our processing function. Its result will be the final grid, updated with all the incrementing done by the flashes, as well as the final set of all flashes, including the original ones.
processFlashes :: (MonadLogger m) =>
HashSet Coord2 -> Seq Coord2 -> OGrid -> m (HashSet Coord2, OGrid)In calling this from our runStep function, we'll prepopulate the visited set and the queue with the initial group of flashes, as well as passing the "incremented" grid.
runStep :: (MonadLogger m) => OGrid -> m (OGrid, Int, Bool)
runStep = do
(allFlashes, newGrid) <- processFlashes (HS.fromList initialFlashes) (Seq.fromList initialFlashes) incrementedGrid
...
where
-- Start by incrementing everything
incrementedGrid = (+1) <$> inputGrid
initialFlashes = fst <$> filter (\(_, x) -> x >= 10) (HM.toList incrementedGrid)Now the last thing we need to do is count the total number of flashes and reset all flashes coordinates to 0 before returning. We can also compare the number of flashes to the size of the hash map to see if they all flashed.
runStep :: (MonadLogger m) => OGrid -> m (OGrid, Int, Bool)
runStep inputGrid = do
(allFlashes, newGrid) <- processFlashes (HS.fromList initialFlashes) (Seq.fromList initialFlashes) incrementedGrid
let numFlashes = HS.size allFlashes
let finalGrid = foldl (\g c -> HM.insert c 0 g) newGrid allFlashes
return (finalGrid, numFlashes, numFlashes == HM.size inputGrid)
where
-- Start by incrementing everything
incrementedGrid = (+1) <$> inputGrid
initialFlashes = fst <$> filter (\(_, x) -> x >= 10) (HM.toList incrementedGrid)Processing Flashes
So now we need to do this flash processing! To re-iterate, this is a BFS problem. We have a queue of coordinates that are flashing. In order to process a single flash, we increment its neighbors and, if incrementing puts its energy over 9, add it to the back of the queue to be processed.
So our inputs are the sequence of coordinates to flash, the current grid, and a set of coordinates we've already visited (since we want to avoid "re-flashing" anything).
processFlashes :: (MonadLogger m) =>
HashSet Coord2 -> Seq Coord2 -> OGrid -> m (HashSet Coord2, OGrid)We'll start with a base case. If the queue is empty, we'll return the input grid and the current visited set.
import qualified Data.Sequence as Seq
import qualified Data.HashSet as HS
import qualified Data.HashMap.Strict as HM
processFlashes :: (MonadLogger m) =>
HashSet Coord2 -> Seq Coord2 -> OGrid -> m (HashSet Coord2, OGrid)
processFlashes visited queue grid = case Seq.viewl queue of
Seq.EmptyL -> return (visited, grid)
...Now suppose we have a non-empty queue and we can pull off the top element. We'll start by getting all 8 neighboring coordinates in the grid and incrementing their values. There's no harm in re-incrementing coordinates that have flashed already, because we'll just reset everything
processFlashes :: (MonadLogger m) =>
HashSet Coord2 -> Seq Coord2 -> OGrid -> m (HashSet Coord2, OGrid)
processFlashes visited queue grid = case Seq.viewl queue of
Seq.EmptyL -> return (visited, grid)
top Seq.:< rest -> do
-- Get the 8 adjacent coordinates in the 2D grid
let allNeighbors = getNeighbors8 grid top
-- Increment the value of all neighbors
newGrid = foldl (\g c -> HM.insert c ((g HM.! c) + 1) g) grid allNeighbors
...Then we want to filter this neighbors list down to the neighbors we'll add to the queue. So we'll make a predicate shouldAdd that tells us if a neighboring coordinate is a.) at least energy level 9 (so incrementing it causes a flash) and b.) that it is not yet visited. This lets us construct our new visited set and the final queue.
processFlashes :: (MonadLogger m) =>
HashSet Coord2 -> Seq Coord2 -> OGrid -> m (HashSet Coord2, OGrid)
processFlashes visited queue grid = case Seq.viewl queue of
Seq.EmptyL -> return (visited, grid)
top Seq.:< rest -> do
let allNeighbors = getNeighbors8 grid top
newGrid = foldl (\g c -> HM.insert c ((g HM.! c) + 1) g) grid allNeighbors
neighborsToAdd = filter shouldAdd allNeighbors
newVisited = foldl (flip HS.insert) visited neighborsToAdd
newQueue = foldl (Seq.|>) rest neighborsToAdd
...
where
shouldAdd :: Coord2 -> Bool
shouldAdd coord = grid HM.! coord >= 9 && not (HS.member coord visited)And, the cherry on top, we just have to make our recursive call with the new values.
processFlashes :: (MonadLogger m) =>
HashSet Coord2 -> Seq Coord2 -> OGrid -> m (HashSet Coord2, OGrid)
processFlashes visited queue grid = case Seq.viewl queue of
Seq.EmptyL -> return (visited, grid)
top Seq.:< rest -> do
let allNeighbors = getNeighbors8 grid top
newGrid = foldl (\g c -> HM.insert c ((g HM.! c) + 1) g) grid allNeighbors
neighborsToAdd = filter shouldAdd allNeighbors
newVisited = foldl (flip HS.insert) visited neighborsToAdd
newQueue = foldl (Seq.|>) rest neighborsToAdd
processFlashes newVisited newQueue newGrid
where
shouldAdd :: Coord2 -> Bool
shouldAdd coord = grid HM.! coord >= 9 && not (HS.member coord visited)With processing done, we have completed our function for running a sinigle step.
Easy Solution
Now that we can run a single step, all that's left is to answer the questions! For the first (easy) part, we just want to count the number of flashes that occur over 100 steps. This will follow a basic recursion pattern, where one of the arguments tells us how many steps are left. The stateful values that we're recursing on are the grid itself, which updates each step, and the sum of the number of flashes.
runStepCount :: (MonadLogger m) => Int -> (OGrid, Int) -> (OGrid, Int)Let's start with a base case. When we have 0 steps left, we return the inputs as the result.
runStepCount :: (MonadLogger m) => Int -> (OGrid, Int) -> m (OGrid, Int)
runStepCount 0 results = return results
...The recursive case is also quite easy. We invoke runStep to get the updated grid and the number of flashses, and then recurse with a reduced step count, adding the new flashes to our previous sum.
runStepCount :: (MonadLogger m) => Int -> (OGrid, Int) -> m (OGrid, Int)
runStepCount 0 results = return results
runStepCount i (grid, prevFlashes) = do
(newGrid, flashCount, _) <- runStep grid
runStepCount (i - 1) (newGrid, flashCount + prevFlashes)And then we can call this from our "easy" entrypoint:
solveDay11Easy :: String -> IO (Maybe Int)
solveDay11Easy fp = do
initialState <- parseFile parse2DDigitHashMap fp
(_, numFlashes) <- runStdoutLoggingT $ runStepCount 100 (initialState, 0)
return $ Just numFlashesHard Solution
For the second part of the problem, we want to find the first step where *all octopuses flash**. Obviously once they synchronize the first time, they'll remain synchronized forever after that. So we'll write a slightly different recursive function, this time counting up instead of down.
runTillAllFlash :: (MonadLogger m) => OGrid -> Int -> m Int
runTillAllFlash inputGrid thisStep = ...Each time we run this function, we'll call runStep. The terminal condition is when the Bool flag we get from runStep becomes true. In this case, we return the current step value.
runTillAllFlash :: (MonadLogger m) => OGrid -> Int -> m Int
runTillAllFlash inputGrid thisStep = do
(newGrid, _, allFlashed) <- runStep inputGrid
if allFlashed
then return thisStep
...Otherwise, we just going to recurse, except with an incremented step count.
runTillAllFlash :: (MonadLogger m) => OGrid -> Int -> m Int
runTillAllFlash inputGrid thisStep = do
(newGrid, _, allFlashed) <- runStep inputGrid
if allFlashed
then return thisStep
else runTillAllFlash newGrid (thisStep + 1)And once again, we wrap up by calling this function from our "hard" entrypoint.
solveDay11Hard :: String -> IO (Maybe Int)
solveDay11Hard fp = do
initialState <- parseFile parse2DDigitHashMap fp
firstAllFlash <- runStdoutLoggingT $ runTillAllFlash initialState 1
return $ Just firstAllFlashAnd now we're done! Our program should be able to solve both parts of the problem!
Conclusion
For the next couple articles, I'll be walking through these same problems, except in video format! So stay tuned for that, and make sure you're subscribed to the YouTube channel so you get notifications about it!
And if you're interested in staying up to date with all the latest news on Monday Morning Haskell, make sure to subscribe to our mailing list. This will get you our monthly newsletter, access to our resources page, and you'll also get special offers on all of our video courses!
Advent of Code: Seven Segment Logic Puzzle
We're into the last quarter of the year, and this means Advent of Code is coming up again in a couple months! I'm hoping to do a lot of these problems in Haskell again and this time do up-to-date recaps. To prepare for this, I'm going back through my solutions from last year and trying to update them and come up with common helpers and patterns that will be useful this year.
You can follow me doing these implementation reviews on my stream, and you can take a look at my code on GitHub here!
Most of my blog posts for the next few weeks will recap some of these problems. I'll do written summaries of solutions as well as video summaries to see which are more clear. The written summaries will use the In-Depth Coding style, so get ready for a lot of code! As a final note, you'll notice my frequent use of MonadLogger, as I covered in this article. So let's get started!
Problem Statement
I'm going to start with Day 8 from last year, which I found to be an interesting problem because it was more of a logic puzzle than a traditional programming problem. The problem starts with the general concept of a seven segment display, a way of showing numbers on an electronic display (like scoreboards, for example).
We can label each of the seven segments like so, with letters "a" through "g":
Segments a-g:
aaaa
b c
b c
dddd
e f
e f
ggggIf all seven segments are lit up, this indicates an 8. If only "c" and "f" are lit up, that's 1, and so on.
The puzzle input consists of lines with 10 "code" strings, and 4 "output" strings, separated by a pipe delimiter:
be cfbegad cbdgef fgaecd cgeb fdcge agebfd fecdb fabcd edb | fdgacbe cefdb cefbgd gcbe
edbfga begcd cbg gc gcadebf fbgde acbgfd abcde gfcbed gfec | fcgedb cgb dgebacf gcThe 10 code strings show a "re-wiring" of the seven segment display. On the first line, we see that be is present as a code string. Since only a "one" has length 2, we know that "b" and "e" each refer either to the "c" or "f" segment, since only those segments are lit up for "one". We can use similar lines of logic to fully determine the mapping of code characters to the original segment display.
Once we have this, we can decode each output string on the right side, get a four-digit number, and then add all of these up.
Solution Approach
When I first solved this problem over a year ago, I went through the effort of deriving a general function to decode any string based on the input codes, and then used this function
However, upon revisiting the problem, I realized it's quite a bit simpler. The length of the output to decode is obviously the first big branching point (as we'll see, "part 1" of the problem clues you on to this). Four of the numbers have unique lengths of "on" segments:
- 2 Segments = 1
- 3 Segments = 7
- 4 Segments = 4
- 7 Segments = 8
Then, three possible numbers have 5 "on" segments (2, 3, and 5). The remaining three (0, 6, 9) use six segments.
However, when it comes to solving these more ambiguous numbers, the key still lies with the digits 1 and 4, because we can always find the codes referring to these by their length. So we can figure out which two code characters are on the right side (referring to the c and fsegments) and which two segments refer to "four minus one", so segments b and d. We don't immediately know which is which in either pair, but it doesn't matter!
Between our "length 5" outputs (2, 3, 5), only 3 contains both segments from "one". So if that isn't true, we can then look at the "four minus one" segments (b and d), and if both are present, it's a 5, otherwise it's a 2.
We can employ similar logic for the length-6 possibilities. If either "one" segment is missing, it must be 6. Then if both "four minus one" segments are present, the answer is 9. Otherwise it is 0.
If this logic doesn't make sense in paragraphs, here's a picture that captures the essential branches of the logic.

So how do we turn this solution into code?
Utilities
First, let's start with a couple utility functions. These functions capture patterns that are useful across many different problems. The first of these is countWhere. This is a small helper whenever we have a list of items and we want the number of items that fulfill a certain predicate. This is a simple matter of filtering on the predicate and taking the length.
countWhere :: (a -> Bool) -> [a] -> Int
countWhere predicate list = length $ filter predicate listNext we'll have a flexible parsing function. In general, I've been trying to use Megaparsec to parse the problem inputs (though it's often easier to parse them by hand). You can read this series to learn more about parsing in Haskell, and this part specifically for megaparsec.
But a good general helper we can have is "given a file where each line has a specific format, parse the file into a list of outputs." I refer to this function as parseLinesFromFile.
parseLinesFromFile :: (MonadIO m) => ParsecT Void Text m a -> FilePath -> m [a]
parseLinesFromFile parser filepath = do
input <- pack <$> liftIO (readFile filepath)
result <- runParserT (sepEndBy1 parser eol) "Utils.hs" input
case result of
Left e -> error $ "Failed to parse: " ++ show e
Right x -> return xTwo key observations about this function. We take the parser as an input (this type is ParsecT Void Text m a). Then we apply it line-by-line using the flexible combinator sepEndBy1 and the eol parser for "end of line". The combinator means we parse several instances of the parser that are separated and optionally ended by the second parser. So each instance (except perhaps the last) of the input parser then is followed by an "end of line" character (or carriage return).
Parsing the Lines
Now when it comes to the specific problem solution, we always have to start by parsing the input from a file (at least that's how I prefer to do it). The first step of parsing is to determine what we're parsing into. What is the "output type" of parsing the data?
In this case, each line we parse consists of 10 "code" strings and 4 "output" strings. So we can make two types to hold each of these parts - InputCode and OutputCode.
data InputCode = InputCode
{ screen0 :: String
, screen1 :: String
, screen2 :: String
, screen3 :: String
, screen4 :: String
, screen5 :: String
, screen6 :: String
, screen7 :: String
, screen8 :: String
, screen9 :: String
} deriving (Show)
data OutputCode = OutputCode
{ output1 :: String
, output2 :: String
, output3 :: String
, output4 :: String
} deriving (Show)Now each different code string can be captured by the parser some letterChar. If we wanted to be more specific, we could even do some like:
choice [char 'a', char 'b', char 'c', char 'd', char 'e', char 'f', char 'g']Now for each group of strings, we'll parse them using the same sepEndBy1 combinator we used before. This time, the separator is hspace, covering horizontal space characters (including tabs, but not newlines). Between these, we use `string "| " to parse the bar in between the input line. So here's the start of our parser:
parseInputLine :: (MonadLogger m) => ParsecT Void Text m (Maybe (InputCode, OutputCode))
parseInputLine = do
screenCodes <- sepEndBy1 (some letterChar) hspace
string "| "
outputCodes <- sepEndBy1 (some letterChar) hspace
...Both screenCodes and outputCodes are lists, and we want to convert them into our output types. So first, we do some validation and ensure that the right number of strings are in each list. Then we can pattern match and group them properly. Invalid results give Nothing.
parseInputLine :: (MonadLogger m) => ParsecT Void Text m (Maybe (InputCode, OutputCode))
parseInputLine = do
screenCodes <- sepEndBy1 (some letterChar) hspace
string "| "
outputCodes <- sepEndBy1 (some letterChar) hspace
if length screenCodes /= 10
then lift (logErrorN $ "Didn't find 10 screen codes: " <> intercalate ", " (pack <$> screenCodes)) >> return Nothing
else if length outputCodes /= 4
then lift (logErrorN $ "Didn't find 4 output codes: " <> intercalate ", " (pack <$> outputCodes)) >> return Nothing
else
let [s0, s1, s2, s3, s4, s5, s6, s7, s8, s9] = screenCodes
[o1, o2, o3, o4] = outputCodes
in return $ Just (InputCode s0 s1 s2 s3 s4 s5 s6 s7 s8 s9, OutputCode o1 o2 o3 o4)Then we can parse the codes using parseLinesFromFile, applying this in both the "easy" part and the "hard" part of the problem.
solveDay8Easy :: String -> IO (Maybe Int)
solveDay8Easy fp = runStdoutLoggingT $ do
codes <- catMaybes <$> parseLinesFromFile parseInputLine fp
...
solveDay8Hard :: String -> IO (Maybe Int)
solveDay8Hard fp = runStdoutLoggingT $ do
inputCodes <- catMaybes <$> parseLinesFromFile parseInputLine fp
...The First Part
Now to complete the "easy" part of the problem, we have to answer the question: "In the output values, how many times do digits 1, 4, 7, or 8 appear?". As we've discussed, each of these has a unique length. So it's easy to first describe a function that can tell from an output string if it is one of these items:
isUniqueDigitCode :: String -> Bool
isUniqueDigitCode input = length input `elem` [2, 3, 4, 7]Then we can use our countWhere utility to apply this function and figure out how many of these numbers are in each output code.
uniqueOutputs :: OutputCode -> Int
uniqueOutputs (OutputCode o1 o2 o3 o4) = countWhere isUniqueDigitCode [o1, o2, o3, o4]Finally, we take the sum of these, applied across the outputs, to get our first answer:
solveDay8Easy :: String -> IO (Maybe Int)
solveDay8Easy fp = runStdoutLoggingT $ do
codes <- catMaybes <$> parseLinesFromFile parseInputLine fp
let result = sum $ uniqueOutputs <$> (snd <$> codes)
return $ Just resultThe Second Part
Now for the hard part! We have to decode each digit in the output, determine its value, and then get the value on the 4-digit display. The root of this is to decode a single string, given the InputCode of 10 values. So let's write a function that does that. We'll use MaybeT since there are some failure conditions on this function.
decodeString :: (MonadLogger m) => InputCode -> String -> MaybeT m IntAs we've discussed, the logic is easy for certain lengths. If the string length is 2, 3, 4 or 7, we have obvious answers.
decodeString :: (MonadLogger m) => InputCode -> String -> MaybeT m Int
decodeString inputCodes output
| length output == 2 = return 1
| length output == 3 = return 7
| length output == 4 = return 4
| length output == 7 = return 8
...Now for length 5 and 6, we'll have separate functions:
decode5 :: (MonadLogger m) => InputCode -> String -> MaybeT m Int
decode6 :: (MonadLogger m) => InputCode -> String -> MaybeT m IntThen we can call these from our base function:
decodeString :: (MonadLogger m) => InputCode -> String -> MaybeT m Int
decodeString inputCodes output
| length output == 2 = return 1
| length output == 3 = return 7
| length output == 4 = return 4
| length output == 7 = return 8
| length output == 5 = decode5 inputCodes output
| length output == 6 = decode6 inputCodes output
| otherwise = mzeroWe have a failure case of mzero if the length doesn't fall within our expectations for some reason.
Now before we can write decode5 and decode6, we'll write a helper function. This helper will determine the two characters present in the "one" segment as well as the two characters present in the "four minus one" segment.
For some reason I separated the two Chars for the "one" segment but kept them together for "four minus one". This probably isn't necessary. But anyways, here's our type signature:
sortInputCodes :: (MonadLogger m) => InputCode -> MaybeT m (Char, Char, String)
sortInputCodes ic@(InputCode c0 c1 c2 c3 c4 c5 c6 c7 c8 c9) = do
...Let's start with some more validation. We'll sort the strings by length and ensure the length distributions are correct.
sortInputCodes :: (MonadLogger m) => InputCode -> MaybeT m (Char, Char, String)
sortInputCodes ic@(InputCode c0 c1 c2 c3 c4 c5 c6 c7 c8 c9) = do
...
where
[sc0, sc1,sc2,sc3,sc4,sc5,sc6,sc7,sc8,sc9] = sortOn length [c0, c1, c2, c3, c4, c5, c6, c7, c8, c9]
validLengths =
length sc0 == 2 && length sc1 == 3 && length sc2 == 4 &&
length sc3 == 5 && length sc4 == 5 && length sc5 == 5 &&
length sc6 == 6 && length sc7 == 6 && length sc8 == 6 &&
length sc9 == 7If the lengths aren't valid, we'll return mzero as a failure case again. But if they are, we'll pattern match to identify our characters for "one" and the string for "four". By deleting the "one" characters, we'll get a string for "four minus one". Then we can return all our items:
sortInputCodes :: (MonadLogger m) => InputCode -> MaybeT m (Char, Char, String)
sortInputCodes ic@(InputCode c0 c1 c2 c3 c4 c5 c6 c7 c8 c9) = do
if not validLengths
then logErrorN ("Invalid inputs: " <> (pack . show $ ic)) >> mzero
else do
let [sc01, sc02] = sc0
let fourMinusOne = delete sc02 (delete sc01 sc2)
return (sc01, sc02, fourMinusOne)
where
[sc0, sc1,sc2,sc3,sc4,sc5,sc6,sc7,sc8,sc9] = sortOn length [c0, c1, c2, c3, c4, c5, c6, c7, c8, c9]
validLengths =
length sc0 == 2 && length sc1 == 3 && length sc2 == 4 &&
length sc3 == 5 && length sc4 == 5 && length sc5 == 5 &&
length sc6 == 6 && length sc7 == 6 && length sc8 == 6 &&
length sc9 == 7Length 5 Logic
Now we're ready to decode a string of length 5! We start by sorting the inputs, and then picking out the three elements from the list that could be of length 5:
decode5 :: (MonadLogger m) => InputCode -> String -> MaybeT m Int
decode5 ic output = do
(c01, c02, fourMinusOne) <- sortInputCodes ic
...So first we'll check if the "one" characters are present, we get 3.
decode5 :: (MonadLogger m) => InputCode -> String -> MaybeT m Int
decode5 ic output = do
(c01, c02, fourMinusOne) <- sortInputCodes ic
-- If both from c0 are present, it's a 3
if c01 `elem` output && c02 `elem` output
then return 3
else ...Then if "four minus one" shares both its characters with the output, the answer is 5, otherwise it is 2.
decode5 :: (MonadLogger m) => InputCode -> String -> MaybeT m Int
decode5 ic output = do
(c01, c02, fourMinusOne) <- sortInputCodes ic
-- If both from c0 are present, it's a 3
if c01 `elem` output && c02 `elem` output
then return 3
else do
let shared = fourMinusOne `intersect` output
if length shared == 2
then return 5
else return 2Length 6 Logic
The logic for length 6 strings is very similar. I wrote it a little differently in this function, but the idea is the same.
decode6 :: (MonadLogger m) => InputCode -> String -> MaybeT m Int
decode6 ic output = do
(c01, c02, fourMinusOne) <- sortInputCodes ic
-- If not both from c0 are present, it's a 6
if not (c01 `elem` output && c02 `elem` output)
then return 6
else do
-- If both of these characters are present in output, 9 else 0
if all (`elem` output) fourMinusOne then return 9 else return 0Wrapping Up
Now that we can decode an output string, we just have to be able to do this for all strings in our output. We just multiply their values by the appropriate power of 10.
decodeAllOutputs :: (MonadLogger m) => (InputCode, OutputCode) -> MaybeT m Int
decodeAllOutputs (ic, OutputCode o1 o2 o3 o4) = do
d01 <- decodeString ic o1
d02 <- decodeString ic o2
d03 <- decodeString ic o3
d04 <- decodeString ic o4
return $ d01 * 1000 + d02 * 100 + d03 * 10 + d04And now we can complete our "hard" function by decoding all these inputs and taking their sums.
solveDay8Hard :: String -> IO (Maybe Int)
solveDay8Hard fp = runStdoutLoggingT $ do
inputCodes <- catMaybes <$> parseLinesFromFile parseInputLine fp
results <- runStdoutLoggingT $ runMaybeT (mapM decodeAllOutputs inputCodes)
return $ fmap sum resultsConclusion
That's all for this week! You can take a look at all this code on GitHub if you want! Here's the main solution module!
Next time, we'll go through another one of these problems! If you'd like to stay up to date with the latest on Monday Morning Haskell, subscribe to our mailing list! This will give you access to all our subscriber resources!
Haskell and Visual Studio
Last time around, we explored how to integrate Haskell with the Vim text editor, which offers a wealth of customization options. With some practice at the keyboard patterns, you can move around files and projects very quickly. But a pure textual editor isn't for everyone. So most of the IDEs out there use graphical interfaces that let you use the mouse.
Today we'll explore one of those options - Visual Studio (aka VS Code). In addition to being graphical, this editor also differs from Vim in that it is a commercial product. As we'll see this brings about some pluses and minuses. One note I'll make is that I'm using VS Code to support Windows Subsystem for Linux, meaning I'm on a Windows machine. A lot of the keyboard shortcuts are different for Mac, so keep that in mind (even beyond simply substituting the "command" key for "control" and "option" for "alt").
Now, let's explore how we can satisfy all the requirements from our original IDE article using this editor!
Basic Features
First off, the basics. Opening new files in new tabs is quite easy. Using "Ctrl+P" brings up a search bar that lets you find anything in your project. Very nice and easy.

I don't like the system of switching between tabs though (at least on a Windows machine). Using "Ctrl+Tab" will take you back to the last file you were in, rather than switching to the next or previous tab as seen on the screen. You can tap it multiple times to scroll through a list, and use "Ctrl+Shift+Tab" to scroll the other direction to access more files. But I would prefer being able to just go to the next and previous tabs. More on that later.

I appreciate that splitting the screen is very easy though. With Ctrl+Alt+Right I can vertically split off the current tab. Then getting it back in place is as easy as Ctrl+Alt+Left.

Visual Studio also comes with a sidebar by default, with no need to install a plugin like with Vim.

Opening the terminal is also easy, using "Ctrl+~". However, this gives a horizontal split, with a terminal on the bottom. I prefer a vertical split to see more errors. And unfortunately, I don't think there's a way to change this (even though there was in previous versions of VS Code).

Remapping Commands
Like Vim, Visual Studio has a way to remap keyboard shortcuts. Using File->Preferences->Keyboard Shortcuts will bring up a menu where you can pick and choose and make some updates.

I made one change, using "Ctrl+B" to close the sidebar, while "Ctrl+Shift+E" can open it.
If you really know what you're doing, you can also open up the file keybindings.json and manually edit them.
However, Visual Studio isn't as flexible as Vim with these remappings. For example, despite my best efforts, I couldn't find a way to remap the keys for switching between tabs. And this was frustrating, since, as I said before, I would prefer a system where I have a combo to go one tab left and one tab right. With VS Code's system, I find there's a lot of inadvertent jumping around that I find unintuitive compared to other systems like Vim.
Extensions
Now, just as Vim has "plugins" to help you add some new, custom functionality to the editor, VS Code has "extensions" that do the same thing. The first thing I did for VS Code (and that I do for any commercial editor) was to install a Vim extension so that I can use the Vim movement keys even in the graphical editor!
VS Code has a large ecosystem of these, and they are quite easy to install - usually just the click of a button, perhaps combined with restarting the editor.

Pretty much all of the Haskell specific functionality we want also comes through an extension. I use this extension just called "Haskell", which works in conjunction with the Haskell Language Server we also used to support Vim. We'll explore its functionality below.
Incidentally, there was another extension that was crucial for my setup of running on Windows Subsystem for Linux. Visual Studio's way of supporting this is actually through SSH. So you need this special Remote WSL extension.
Language Specific Features
Now let's see the Haskell extension in action. As in Vim, we get notified of compile errors:
And we also get squiggly lines to indicate lint suggestions. I like the blue highlighting much better than the yellow text from Vim..
You can also get library suggestions like in Vim, but this time the documentation doesn't appear.

By far the biggest win with Visual Studio is that the extension can autocorrect certain issues, especially missing imports. When you use a new function that it can find in your project or a library, it will bring up this menu and let you fix it with "Ctrl+.". This helps so much with maintaining development flow and now having to scroll back to the top to add the import yourself. It's probably my favorite aspect of using VS Code.

A final area where Visual Studio could offer improvements is with its build systems. It's possible to configure VS to have "Build" and "Test" processes that you can run with assigned keyboard shortcuts. However, I couldn't get these to work with WSL. You have to assign a "stack" executable path. But I think with VS operating in Windows, it rejects the linux version of this file. So I couldn't get those features working. But they might still be possible, especially on Mac.
Conclusions
So all in all, Visual Studio has some nice conveniences. Installing plugins is a bit easier, and the quick correction of issues like imports is very nice. But it's not as customizable as Vim, especially with keyboard shortcuts.
Additionally, since it's a commercial product, Microsoft collects various usage data whenever you use Visual Studio. Certain users might not like this and prefer open source programs as a result. There's a free version of VS called VSCodium, but it lacks most of the useful extensions and is harder to install and use.
And of course there are many other editors out there with viable Haskell extensions, most notably emacs. But I'll leave those for another day.
Make sure to subscribe to stay up to date with all the latest on Monday Morning Haskell! This will give you access to our Subscriber Resources, like our Beginners Checklist!
Using Haskell in Vim: The Basics
Last week I went over some of the basic principles of a good IDE setup. Now in this article and the next, we're going to do this for Haskell in a couple different environments.
A vital component of almost any Haskell setup (at least the two we'll look at) is getting Haskell Language Server running and being able to switch your global GHC version. We covered all that in the last article with GHCup.
In this article we'll look at creating a Haskell environment in Vim. We'll cover how Vim allows us to perform all the basic actions we want, and then we'll add some of the extra Haskell features we can get from using HLS in conjunction with a plugin.
One thing I want to say up front, because I know how frustrating it can be to try repeating something from an article and have it not work: this is not an exhaustive tutorial for installing Haskell in Vim. I plan to do a video on that later. There might be extra installation details I'm forgetting in this article, and I've only tried this on Windows Subsystem for Linux. So hopefully in the future I'll have time to try this out on more systems and have a more detailed look at the requirements.
Base Features
But, for now, let's start checking off the various boxes from last week's list. We had an original list of 7 items for basic functionality. Here are five of them:
- Open a file in a tab
- Switch between tabs
- Open files side-by-side (and switch between them)
- Open up a terminal to run commands
- Switch between the terminal and file to edit
Now Vim is a textual editor, meant to be run from a command prompt or terminal. Thus you can't really use the mouse at all in Vim! This is disorienting at first, but it means that all of these actions we have to take must have keyboard commands. Once you learn all these, your coding will get much faster!
To open a new file in a tab, we would use :tabnew followed by the file name (and we can use autocomplete to get the right file). We can then flip between tabs with the commands :tabn (tab-next) and :tabp (tab-previous).
To see multiple files at the same time, we can use the :split command, followed by the file name. This gives a horizontal split. My preference is for a vertical split, which is achieved with :vs and the file name. Instead of switching between files with :tabn and :tabp, we use the command Ctrl+W to go back and forth.
Finally, we can open a terminal using the :term command. By default, this puts the terminal at the bottom of the screen:
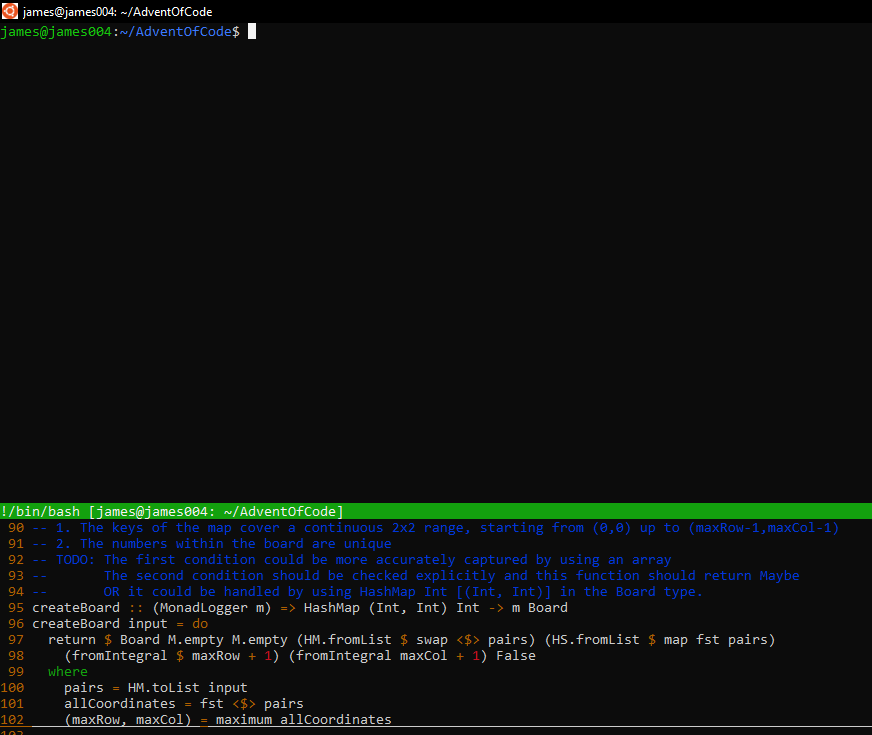
We can also get a side-by-side terminal with :vert term.
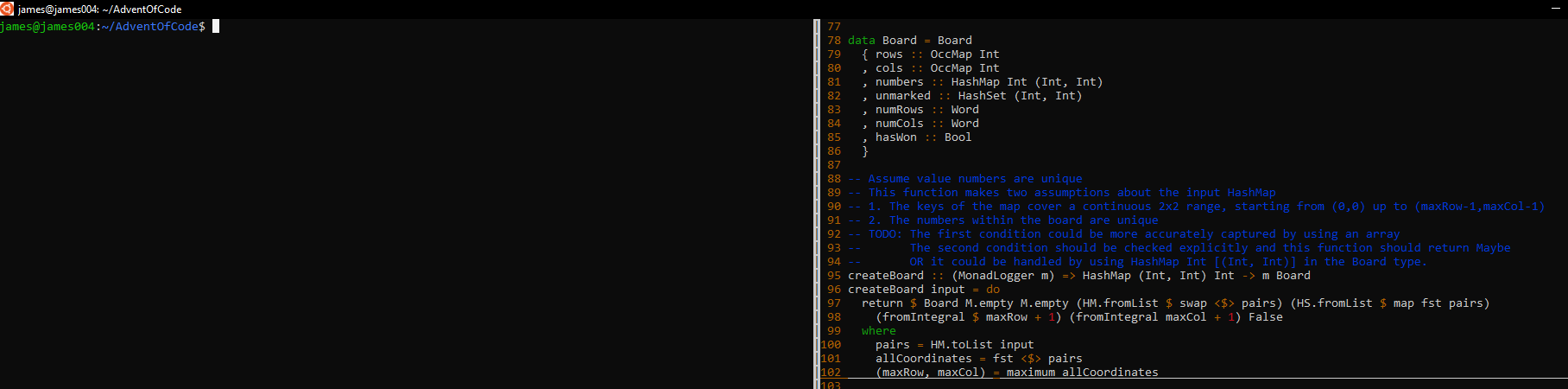
Switching between terminals is the same as switching between split screens: Ctrl+WW.
And of course, obviously, Vim has "Vim movement" keys so you can move around the file very quickly!
Sidebar Support
Now the two other items on the list are related to having a sidebar, another useful base feature in your IDE.
- Open & close a navigation sidebar
- Use sidebar to open files
We saw above that it's possible to open new files. But on larger projects, you can't keep the whole project tree in your head, so you'll probably need a graphical reference to help you.
Vim doesn't support such a layout natively. But with Vim (and pretty much every editor), there is a rich ecosystem of plugins and extensions to help improve the experience.
In fact, with Vim, there are multiple ways of installing plugins. The one I ended up deciding on is Vim Plug. I used it to install a Plugin called NerdTree, which gives a nice sidebar view where I can scroll around and open files.
In general, to make a modification to your Vim settings, you modify a file in your home directory called .vimrc. To use NerdTree (after installing Vim Plug), I just added the following lines to that file.
call plug#begin('~/.vim/plugged")
Plug 'preservim/nerdtree'
call plug#end()Here's what it looks like:
All that's needed to bring this menu up is the command :NERDTree. Switching focus remains the same with Ctrl+WW and so does closing the tab with :q.
Configurable Commands
Another key factor with IDEs is being able to remap commands for your own convenience. I found some of Vim's default commands a bit cumbersome. For example, switching tabs is a common enough task that I wanted to make it really fast. I wanted to do the same with opening the terminal, while also doing so with a vertical split instead of the default horizontal split. Finally, I wanted a shorter command to open the NerdTree sidebar.
By putting the following commands in my .vimrc file, I can get these remappings:
nnoremap <Leader>q :tabp<CR>
nnoremap <Leader>r :tabn<CR>
nnoremap <Leader>t :vert term<CR>
nnoremap <Leader>n :NERDTree<CR>In these statements, <Leader> refers to a special key that is backslash (\) by default, but also customizable. So now I can switch tabs using \q and \r, open the terminal with \t, and open the sidebar with \n.
Language Specific Features
Now the last (and possibly most important) aspect of setting up the IDE is to get the language-specific features working. Luckily, from the earlier article, we already have the Haskell Language Server running thanks to GHCup. Let's see how to apply this with Vim.
First, we need another Vim plugin to work with the language server. This plugin is called "CoC", and we can install it by including this line in our .Vimrc in the plugins section:
call plug#begin('~/.vim/plugged')
...
Plug 'neoclide/coc.nvim', {'branch': 'release'}
call plug#end()After installing the plugin (re-open .vimrc or :source the file), we then have to configure the plugin to use the Haskell Language Server. To do this, we have to use the :CocConfig command within Vim, and then add the following lines to the file:
{
"languageserver": {
"haskell": {
"command": "haskell-language-server-wrapper",
"args": ["--lsp"],
"rootPatterns": ["*.cabal", "stack.yaml", "cabal.project", "package.yaml", "hie.yaml"],
"filetypes": ["haskell", "lhaskell"]
}
}
}Next, we have to use GHCup to make sure the "global" version of GHC matches our project's version. So, as an example, we can examine the stack.yaml file and find the resolver:
resolver:
url: https://raw.githubusercontent.com/commercialhaskell/stackage-snapshots/master/lts/19/13.yamlThe 19.13 resolver corresponds to GHC 9.0.2, so let's go ahead and set that using GHCup:
>> ghcup set ghc 9.0.2And now we just open our project file and we can start seeing Haskell tips! Here's an example showing a compilation error:

The ability to get autocomplete suggestions from library functions works as well:

And we can also get a lint suggestion (I wish it weren't so "yellow"):

Note that in order for this to work, you must open your file from the project root where the .cabal file is. Otherwise HLS will not work correctly!
# This works!
>> cd MyProject
>> vim src/MyCode.hs
# This does not work!
>> cd MyProject/src
>> vim MyCode.hsConclusion
That's all for our Haskell Vim setup! Even though this isn't a full tutorial, hopefully this gives you enough ideas that you can experiment with Haskell in Vim for yourself! Next time, we'll look at getting Haskell working in Visual Studio!
If you want to keep up to date with all the latest on Monday Morning Haskell, make sure to subscribe to our mailing list! This will also give you access to our subscriber resources, including beginner friendly resources like our Beginners Checklist!