From World to Environment: Open AI Gym Primer

In last week's article, we briefly entered the world of Haskell's Gloss library and illustrated our search algorithm in action. An integral part of this process was creating and using a particular World type to store information about the state of our game and process updates.
This week we'll discuss the Open AI Gym. This framework is widely used to help people learn about AI algorithms and how to train them using machine learning techniques. It has its own concept of an "environment" that is very similar to this "World" idea. It's worth comparing these concepts, and it's especially fun to consider how to re-create the "environment" in Haskell. This is a (somewhat) novel area where type families can help us out. So read on to learn how!
You can see all the code for this series on GitHub! For this article, you should look at the Environment module. This article is also available as a video on YouTube!
Review of World Type
Let's recall our World type from last time:
data World = World
{ playerLocation :: Location
, startLocation :: Location
, endLocation :: Location
, worldGrid :: Grid
}This type stores all the information, both mutable and immutable, about our game. It tells us the grid that we are navigating, as well as the current location of the "player", which can change.
Our game then is largely defined by functions that operate on this world:
play :: Display -> Color -> Int
-> world
-> (world -> Picture)
-> (Event -> world -> world)
-> (Float -> world -> world)
-> IO ()
drawingFunc :: World -> Picture
inputHandler :: Event -> World -> World
updateFunc :: Float -> World -> WorldWe require a function to draw our world, a function to change the world based on user actions, and a function to let the world evolve naturally. And, of course, we need to create our initial world in order to start the game off.
Open Gym Environment
Now let's compare that to some code from Open AI Gym. Here's a Python snippet you can find on the Open AI Gym website:
import gym
env = gym.make("CartPole-v1")
observation = env.reset()
for _ in range(1000):
env.render()
action = env.action_space.sample() # Takes a random action
observation, reward, done, info = env.step(action)
if done:
observation = env.reset()
env.close()Let's note how this environment is used:
We create it ("make") and can "reset" it. Resetting it produces an "observation". The environment has an "action space", a set of available actions. We can "step" the environment forward using one of these actions, producing a new observation, a reward, and a boolean indicating if we're "done". We can "render" the environment.
Like our World, an environment clearly stores all the information about a game. But we also have this subset of information that we refer to as the "observation". This, generally speaking, is information a player of the game actually has access to, and it ought to be mutable.
Next, we "step" the game forward using one of the possible actions at a point. This is a combination of the input handler and update function from our Gloss example. When we step forward, we usually impact the world with our action, but the world also goes through its own natural evolution. This produces a new observation from which we'll base our next action.
We also see a "reward" as a result of each action. This is something unique to the environment. Rewards are very important in training any kind of algorithm using machine learning. It's how we tell our program what a "good" move is.
And of course, it's useful to be able to render or draw our environment, though this isn't strictly necessary for the game's logic.
Making a Haskell Environment
There's a distinct drawback of using Python though. The types of several of our environment-related expressions above are unclear! What information, exactly, is stored in the environment? What does an "action" look like, or an "observation"? In very basic games, both the action and observation can be simple integers, but it's tricky to make heads or tails of that.
So let's consider what an "Environment" with this kind of API would look like in Haskell. We're tempted of course, to make this a specific type. But we don't have type-level inheritance in Haskell. And we'll want to create some kind of pattern that different games can inherit from. So it's actually better to make this a typeclass. And, since our game will need to have different side effects, we'll make it a monadic typeclass:
class (Monad m) => EnvironmentMonad m where
...And this is where the fun begins! Each different game environment will have its types associated with it, corresponding to the environment state, an action, and an observation. So we can use type family syntax to associate these types with the class variable m:
class (Monad m) => EnvironmentMonad m where
type Observation m :: *
type Action m :: *
type EnvironmentState m :: *
...We can use these types within our other class functions as well. For example, we should be able to produce the current observation. And given an observation, we should be able to describe the available actions. We should also be able to reset the environment.
class (Monad m) => EnvironmentMonad m where
type Observation m :: *
type Action m :: *
type EnvironmentState m :: *
currentObservation :: m (Observation m)
possibleActions :: Observation m -> m [Action m]
resetEnv :: m (Observation m)
...Finally, we need two more items. First, our "step" function. This takes an action as input, and it produces a new observation, a reward, and a boolean, indicating that we are done. Then the last item will be more Haskell specific. This will be a "run" function. It will allow us to take an action in our monad, combined with the environment state, and turn it into a normal IO action we can run elsewhere.
newtype Reward = Reward Double
class (Monad m) => EnvironmentMonad m where
type Observation m :: *
type Action m :: *
type EnvironmentState m :: *
currentObservation :: m (Observation m)
possibleActions :: Observation m -> m [Action m]
resetEnv :: m (Observation m)
stepEnv :: (Action m) -> m (Observation m, Reward, Bool)
runEnv :: (EnvironmentState m) -> m a -> IO aIf we are interested in rendering our environment, we can make a new typeclass that inherits from our base class. It should also inherit from IO, because any kind of rendering will involve IO.
class (MonadIO m, EnvironmentMonad m) => RenderableEnvironment m where
renderEnv :: m ()Using this class, we can write some generic code that will work on any game! Here's a couple loop functions. This first will work on any environment, though it requires we supply our own function to choose an action. This is really the "brain" of the game, which we'll get into more next time!
gameLoop ::
(EnvironmentMonad m) => m (Action m) -> m (Observation m, Reward)
gameLoop chooseAction = do
newAction <- chooseAction
(newObs, reward, done) <- stepEnv newAction
if done
then return (newObs, reward)
else gameLoop chooseActionAnd if we want to render our game each time, we can just add this separate constraint, and add the extra render steps in between!
gameRenderLoop :: (RenderableEnvironment m) => m (Action m) -> m (Observation m, Reward)
gameRenderLoop chooseAction = do
renderEnv
newAction <- chooseAction
(newObs, reward, done) <- stepEnv newAction
if done
then renderEnv >> return (newObs, reward)
else gameRenderLoop chooseActionConclusion
So there are a lot of similarities between these two systems, but clearly Open AI Gym is a little more involved and detailed. But Haskell provides some interesting mechanisms for us to add more type-clarity around our environments.
Next week, we'll actually use this environment class and apply it to our simple Breadth-First-Search example. This will really get us started on the road to applying machine learning to this problem, so you won't want to miss out! Make sure to subscribe to Monday Morning Haskell so you can stay up to date with what's going on here!
See and Believe: Visualizing with Gloss

Last week I discussed AI for the first time in a while. We learned about the Breadth-First-Search algorithm (BFS) which is so useful in a lot of simple AI applications. But of course writing abstract algorithms isn't as interesting as seeing them in action. So this week I'll re-introduce Gloss, a really neat framework I've used to make some simple games in Haskell.
This framework simplifies a lot of the graphical work one needs to do to make stuff show up on screen and it allows us to provide Haskell code to back it up and make all the logic interesting. I think Gloss also gives a nice demonstration of how we really want to structure a game and, in some sense, any kind of interactive program. We'll break down how this structure works as we make a simple display showing the BFS algorithm in practice. We'll actually have a "player" piece navigating a simple maze by itself.
To see the complete code, take a look at this GitHub repository! The Gloss code is all in the Game module.
Describing the World
In Haskell, the first order of business is usually to define our most meaningful types. Last week we did that by specifying a few simple aliases and types to use for our search function:
type Location = (Int, Int)
data Cell = Empty | Wall
deriving (Eq)
type Grid = A.Array Location CellWhen we're making a game though, there's one type that is way more important than the rest, and this is our "World". The World describes the full state of the game at any point, including both mutable and immutable information.
In describing our simple game world, we might view three immutable elements, the fundamental constraints of the game. These are the "start" position, the "end" position, and the grid itself. However, we'll also want to describe the "current" position of our player, which can change each time it moves. This gives us a fourth field.
data World = World
{ playerLocation :: Location
, startLocation :: Location
, endLocation :: Location
, worldGrid :: Grid
}We can then supplement this by making our "initial" elements. We'll have a base grid that just puts up a simple wall around our destination, and then make our starting World.
-- looks like:
-- S o o o
-- o x x o
-- o x F o
-- o o o o
baseGrid :: Grid
baseGrid =
(A.listArray ((0, 0), (3, 3)) (replicate 16 Empty))
A.//
[((1, 1), Wall), ((1, 2), Wall), ((2, 1), Wall)]
initialWorld :: World
initialWorld = World (0, 0) (0, 0) (2, 2) baseGridPlaying the Game
We've got our main type in place, but we still need to pull it together in a few different ways. The primary driver function of the Gloss library is play. We can see its signature here.
play :: Display -> Color -> Int
-> world
-> (world -> Picture)
-> (Event -> world -> world)
-> (Float -> world -> world)
-> IO ()The main pieces of this are driven by our World type. But it's worth briefly addressing the first three. The Display describes the viewport that will show up on our screen. We can give it particular dimensions and offset:
windowDisplay :: Display
windowDisplay = InWindow "Window" (200, 200) (10, 10)The next two values just indicate the background color of the screen, and the tick rate (how many game ticks occur per second). And after those, we just have our initial world value as we made above.
main :: IO ()
main = play
windowDisplay white 1 initialWorld
...But now we have three more functions that are clearly driven by our World type. The first is a drawing function. It takes the current state of the world and create a Picture to show on screen.
The second function is an input handler, which takes a user input event as well as the current world state, and returns an updated world state, based on the event. We won't address this in this article.
The third function is an update function. This describes how the world naturally evolves without any input from tick to tick.
For now, we'll make type signatures as we prepare to implement these functions for ourselves. This allows us to complete our main function:
main :: IO ()
main = play
windowDisplay white 20 initialWorld
drawingFunc
inputHandler
updateFunc
drawingFunc :: World -> Picture
inputHandler :: Event -> World -> World
updateFunc :: Float -> World -> WorldLet's move on to these different world-related functions.
Updating the World
Now let's handle updates to the world. To start, we'll make a stubbed out input-handler. This will just return the input world each tick.
inputHandler :: Event -> World -> World
inputHandler _ w = wNow let's describe how the world will naturally evolve/update with each game tick. For this step, we'll apply our BFS algorithm. So all we really need to do is retrieve the locations and grid out of the world and run the function. If it gives us a non-empty list, we'll substitute the first square in that path for our new location. Otherwise, nothing happens!
updateFunc :: Float -> World -> World
updateFunc _ w@(World playerLoc _ endLoc grid time) =
case path of
(first : rest) -> w {playerLocation = first}
_ -> w
where
path = bfsSearch grid playerLoc endLocNote that this function receives an extra "float" argument. We don't need to use this.
Drawing
Finally, we need to draw our world so we can see what is going on! To start, we need to remember the difference between the "pixel" positions on the screen, and the discrete positions in our maze. The former are floating point values up to (200.0, 200.0), while the latter are integer numbers up to (3, 3). We'll make a type to store the center and corner points of a given cell, as well as a function to generate this from a Location.
A lot of this is basic arithmetic, but it's easy to go wrong with sign errors and off-by-one errors!
data CellCoordinates = CellCoordinates
{ cellCenter :: Point
, cellTopLeft :: Point
, cellTopRight :: Point
, cellBottomRight :: Point
, cellBottomLeft :: Point
}
-- First param: (X, Y) offset from the center of the display to center of (0, 0) cell
-- Second param: Full width of a cell
locationToCoords :: (Float, Float) -> Float -> Location -> CellCoordinates
locationToCoords (xOffset, yOffset) cellSize (x, y) = CellCoordinates
(centerX, centerY)
(centerX - halfCell, centerY + halfCell) -- Top Left
(centerX + halfCell, centerY + halfCell) -- Top Right
(centerX + halfCell, centerY - halfCell) -- Bottom Right
(centerX - halfCell, centerY - halfCell) -- Bottom Left
where
(centerX, centerY) = (xOffset + (fromIntegral x) * cellSize, yOffset - (fromIntegral y) * cellSize)
halfCell = cellSize / 2.0Now we need to use these calculations to draw pictures based on the state of our world. First, let's write a conversion that factors in the specifics of the display, which allows us to pinpoint the center of the player marker.
drawingFunc :: World -> Picture
drawingFunc world =
...
where
conversion = locationToCoords (-75, 75) 50
(px, py) = cellCenter (conversion (playerLocation world))Now we can draw a circle to represent that! We start by making a Circle that is 10 pixels in diameter. Then we translate it by the coordinates. Finally, we'll color it red. We can add this to a list of Pictures we'll return.
drawingFunc :: World -> Picture
drawingFunc world = Pictures
[ playerMarker ]
where
-- Player Marker
conversion = locationToCoords (-75, 75) 50
(px, py) = cellCenter (conversion (playerLocation world))
playerMarker = Color red (translate px py (Circle 10))Now we'll make Polygon elements to represent special positions on the board. Using the corner elements from CellCoordinates, we can draw a blue square for the start position and a green square for the final position.
drawingFunc :: World -> Picture
drawingFunc world = Pictures
[startPic, endPic, playerMarker ]
where
-- Player Marker
conversion = locationToCoords (-75, 75) 50
(px, py) = cellCenter (conversion (playerLocation world))
playerMarker = Color red (translate px py (Circle 10))
# Start and End Pictures
(CellCoordinates _ stl str sbr sbl) = conversion (startLocation world)
startPic = Color blue (Polygon [stl, str, sbr, sbl])
(CellCoordinates _ etl etr ebr ebl) = conversion (endLocation world)
endPic = Color green (Polygon [etl, etr, ebr, ebl])Finally, we do the same thing with our walls. First we have to filter all the elements in the grid to get the walls. Then we must make a function that will take the location and make the Polygon picture. Finally, we combine all of these into one picture by using a Pictures list, mapped over these walls. Here's the final look of our function:
drawingFunc :: World -> Picture
drawingFunc world = Pictures
[gridPic, startPic, endPic, playerMarker ]
where
-- Player Marker
conversion = locationToCoords (-75, 75) 50
(px, py) = cellCenter (conversion (playerLocation world))
playerMarker = Color red (translate px py (Circle 10))
# Start and End Pictures
(CellCoordinates _ stl str sbr sbl) = conversion (startLocation world)
startPic = Color blue (Polygon [stl, str, sbr, sbl])
(CellCoordinates _ etl etr ebr ebl) = conversion (endLocation world)
endPic = Color green (Polygon [etl, etr, ebr, ebl])
# Drawing the Pictures for the Walls
walls = filter (\(_, w) -> w == Wall) (A.assocs $ worldGrid world)
mapPic (loc, _) = let (CellCoordinates _ tl tr br bl) = conversion loc
in Color black (Polygon [tl, tr, br, bl])
gridPic = Pictures (map mapPic walls)And now when we play the game, we'll see our circle navigate to the goal square!

Next time, we'll look at a more complicated version of this kind of game world!
AI Revisited: Breaking Down BFS

So we're approaching the end of the year, and of all the topics that I've tended to focus on in my writings, there's one that I haven't really written about in probably over a year, and this is AI and Machine Learning. I've still been doing some work behind the scenes, as you'll know if you keep following the blog for the next few weeks. But I figured I'd spend the last few weeks of the year with some AI related topics. This week, I'll go over an algorithm that is really useful to understand when it comes to writing simple AI programs, and this is Breadth-First-Search.
All the code for the next few weeks can be found in this GitHub repository! For this week, all the code can be found in the BFS module.
The Algorithm
To frame this problem in a more concrete way, let's imagine we have a 2-dimensional grid. Some spaces are free, other spaces are "walls". We want to use breadth first search to find a path from a start point to a destination point.
a___
_xx_
_xb_
____So our algorithm will take two locations, and return a path from location A to Location B, or an empty list if no path can be found.
The key data structure when executing a breadth-first-search is a queue. Our basic approach is this: we will place our starting location in the queue. Then, we'll go through a loop as long as the queue is not empty. We'll pull an item off, and then add each of the empty neighbors on to the back of the queue, as long as they haven't been added yet. If we dequeue the destination, we're done! But if we reach an empty queue, then we don't have a valid path.
The last tricky part is that we to track the "parent" of each location. That is, which of its neighbors placed it on the queue? This will allow us to reconstruct the path we need to take to get from point a to point b.
So let's imagine we have a simple graph like in the ASCII art above. We start at (0,0). Our queue will operate like this.
It contains (0,0). We'll then enqueue (0, 1) and (1, 0), since those are the neighbors of (0, 0).
(0, 0) <-- Current
(0, 1)
(1, 0)Then we're done with (0, 0). So we dequeue (0, 1). This its only neighbor is (0, 2), so that gets placed on the end of the queue.
(0, 1) <-- Current
(1, 0)
(0, 2)And then we repeat the process with (1, 0), placing (0, 2).
(1, 0) <-- Current
(0, 2)
(2, 0)We keep doing this until we navigate around to our destination at (2,2).
Types First
How do we translate this to Haskell? My favorite approach to problems like this is to use a top-down, type driven, compile-first method of writing the algorithm. Because before we can really get started in earnest, we have to define our data structures and our types. First, let's alias an integer tuple as a "Location":
type Location = (Int, Int)Now, we're going to imagine we're navigating a 2D grid, and we'll represent this with an array where the indices are tuples which represent locations, and each value is either "empty" or "wall". We can move through empty spaces, but we cannot move through walls.
data Cell = Empty | Wall
deriving (Eq)
type Grid = A.Array Location CellNow we're ready to define the type signature for our function. This takes the grid as an input, as well as the start and end location:
bfsSearch :: Grid -> Location -> Location -> [Location]We'll need one more type to help frame the problem. This algorithm will use the State monad, because there's a lot of state we need to track here. First off, we need the queue itself. We represent this with the Sequence type in Haskell. Then, we need our set of visited locations. Each time we enqueue a location, we'll save it here. Last, we need our "parents" map. This will help us determine the path at the very end.
data BFSState = BFSState
{ queue :: S.Seq Location
, visited :: Set.Set Location
, parents :: M.Map Location Location
}A Stateful Skeleton
With these types, we can start framing the problem a bit more. First, we want to construct our initial state. Everything is empty except our queue has the starting location on it.
bfsSearch :: Grid -> Location -> Location -> [Location]
bfsSearch grid start finish = ...
where
initialState = BFSState (S.singleton start) Set.empty M.emptyNow we want to pass this function to a stateful computation that returns our list. So we'll imagine we have a helper in the State monad which returns our location. We'll call this bfsSearch'. We can then fill in our original function with evalState.
bfsSearch :: Grid -> Location -> Location -> [Location]
bfsSearch grid start finish = evalState (bfsSearch' grid finish) initialState
where
initialState = BFSState (S.singleton start) Set.empty M.empty
bfsSearch' :: Grid -> Location -> State BFSState [Location]
...Base Case
Now within our stateful helper, we can recognize that this will be a recursive function. We dequeue an element, enqueue its neighbors, and then repeat the process. So let's handle the base cases first. We'll retrieve our sequence from the state and check if it's empty or not. If it's empty, we return the empty list. This means that we couldn't find a path.
bfsSearch' :: Grid -> Location -> State BFSState [Location]
bfsSearch' grid finish = do
(BFSState q v p) <- get
case S.viewl q of
(top S.:< rest) -> ...
_ -> return []Now another base case is where the top of our queue is the destination. In this case, we're ready to "unwind" the path from that destination in our stateful map. Let's imagine we have a function to handle this unwinding process. We'll fill it in later.
bfsSearch' :: Grid -> Location -> State BFSState [Location]
bfsSearch' grid finish = do
(BFSState q v p) <- get
case S.viewl q of
(top S.:< rest) -> if top == finish
then return (unwindPath p [finish])
else ...
_ -> return []
unwindPath :: M.Map Location Location -> [Location] -> [Location]The General Case
Now let's write out the steps for our general case.
- Get the neighbors of the top element on the queue
- Append these to the "rest" of the queue (discarding the top element).
- Insert this top element into our "visited" set
v. - For each new location, insert it into our "parents" map with the current top as its "parent".
- Update our final state and recurse!
Each of these statements is 1-2 lines in our function, except we'll want to make a helper for the first line. Let's imagine we have a function that can give us the unvisited neighbors of a space in our grid. This will require passing the location, the grid, and the visited set.
let valid adjacent = getValidNeighbors top grid v
...
getValidNeighbors ::
Location -> Grid -> Set.Set Location -> [Location]The next lines involve data structure manipulation, with a couple tricky folds. First, appending the new elements into the queue.
let newQueue = foldr (flip (S.|>)) rest validAdjacentNext, inserting the top into the visited set. This one's easy.
let newVisited = Set.insert top vNow, insert each new neighbor into the parents map. The new location is the "key", and the current top is the value.
let newParentsMap = foldr (\loc -> M.insert loc top) p validAdjacentLast of all, we replace the state and recurse!
put (BFSState newQueue newVisited newParentsMap)
bfsSearch' grid finishHere's our complete function!
bfsSearch' :: Grid -> Location -> State BFSState [Location]
bfsSearch' grid finish = do
(BFSState q v p) <- get
case S.viewl q of
(top S.:< rest) -> if top == finish
then return (unwindPath p [finish])
else do
let validAdjacent = getValidNeighbors top grid v
let newQueue = foldr (flip (S.|>)) rest validAdjacent
let newVisited = Set.insert top v
let newParentsMap = foldr (\loc -> M.insert loc top) p validAdjacent
put (BFSState newQueue newVisited newParentsMap)
bfsSearch' grid finish
_ -> return []Filling in Helpers
Now we just need to fill in our helper functions. Unwinding the map is a fairly straightforward tail-recursive problem. We get the parent of the current element, and keep an accumulating list of the places we've gone:
unwindPath :: M.Map Location Location -> [Location] -> [Location]
unwindPath parentsMap currentPath = case M.lookup (head currentPath) parentsMap of
Nothing -> tail currentPath
Just parent -> unwindPath parentsMap (parent : currentPath)Finding the neighbors is slightly tricker. For each direction (right, down, left, and right), we have to consider if the "neighbor" cell is in bounds. Then we have to consider if it's empty. Finally, we need to know if it is still "unvisited". As long as all three of these conditions hold, we can potentially add it. Here's what this process looks like for finding the "right" neighbor.
getValidNeighbors :: Location -> Grid -> Set.Set Location -> [Location]
getValidNeighbors (r, c) grid v = ...
where
(rowMax, colMax) = snd . A.bounds $ grid
right = (r, c + 1)
right' = if c + 1 <= colMax && grid A.! right == Empty && not (Set.member right v)
then Just right
else NothingWe do this in every direction, and we'll use catMaybes so we only get the correct ones in the end!
getValidNeighbors :: Location -> Grid -> Set.Set Location -> [Location]
getValidNeighbors (r, c) grid v = catMaybes [right', down', left', up']
where
(rowMax, colMax) = snd . A.bounds $ grid
right = (r, c + 1)
right' = if c + 1 <= colMax && grid A.! right == Empty && not (Set.member right v)
then Just right
else Nothing
down = (r + 1, c)
down' = if r + 1 <= rowMax && grid A.! down == Empty && not (Set.member down v)
then Just down
else Nothing
left = (r, c - 1)
left' = if c - 1 >= 0 && grid A.! left == Empty && not (Set.member left v)
then Just left
else Nothing
up = (r - 1, c)
up' = if r - 1 >= 0 && grid A.! up == Empty && not (Set.member up v)
then Just up
else NothingConclusion
This basic structure can also be adapted to use depth-first search as well! The main difference is that you must treat the Sequence as a stack instead of a queue, appending new items to the left side of the sequence. Both of these algorithms are guaranteed to find a path if it exists. But BFS will find the shortest path in this kind of scenario, whereas DFS probably won't!
Next week, we'll continue a basic AI exploration by putting this algorithm to work in a game environment with Gloss!
Monads want to be Free!

(This post is also available as a YouTube video)!
In last week's article I showed how we can use monad classes to allow limited IO effects in our functions. That is, we can get true IO functionality for something small (like printing to the terminal), without allowing a function to run any old IO action (like reading from the file system). In this way monad classes are the building blocks of Haskell's effect structures.
But there's another idea out there called "free monads". Under this paradigm, we can represent our effects with a data type, rather than a typeclass, and this can be a nicer way to conceptualize the problem. In this article I'll show how to use free monads instead of monad classes in the same Nim game example we used last time.
The "starter" code for this article is on the monad-class branch here.
The "ending" code is on the eff branch.
And here is a pull request showing all the edits we'll make!
Intro to Free Monads
Free monads are kind of like Haskell Lenses in that there are multiple implementations out there for the same abstract concept. I'm going to use the Freer Effects library. If you use a different implementation, the syntax details might be a bit different, but the core ideas should still be the same.
The first thing to understand about using free monads, at least with this library, is that there's only a single monad, which we call the Eff monad. And to customize the behavior of this monad, it's parameterized by a type level list containing different effects. Now, we can treat any monad like an effect. So we can construct an instance of this Eff monad that contains the State monad over our game state, as well as the IO monad.
playGame :: Eff '[State (Player, Int), IO ] PlayerNow in order to use monadic functionality within our Eff monad, we have the use the send function. So let's write a couple helpers for the state monad to demonstrate this.
getState :: (Member (State (Player, Int)) r) => Eff r (Player, Int)
getState = send (get :: State (Player, Int) (Player, Int))
putState :: (Member (State (Player, Int)) r) => (Player, Int) -> Eff r ()
putState = send . (put :: (Player, Int) -> State (Player, Int) ())Whereas a typical monad class function won't specify the complete monad m, in this case, we won't specify the complete effect list. We'll just call it r. But then we'll place what is called a Member constraint on this function. We'll say that State (Player, Int) must be a "member" of the effect list r. Then we can just use send in conjunction with the normal monadic functions. We can also add in some type specifiers to make things more clear for the compiler.
Creating an Effect Type
But now let's think about our MonadTerminal class from last time. This doesn't correspond to a concrete monad, so how would we use it? The answer is that instead of using a typeclass, we're going to make a data type representing this effect, called Terminal. This will be a generalized algebraic data type, or GADT. So its definition actually kind of does look like a typeclass. Notice this seemingly extra a parameter as part of the definition.
data Terminal a where
LogMessage :: String -> Terminal ()
GetInputLine :: Terminal StringNow we capitalized our function names to make these data constructors. So let's write functions now under the original lowercase names that will allow us to call these constructors. These functions will look a lot like our state functions. We'll say that Terminal must be a member of the type list r. And then we'll just use send except we'll use it with the appropriate constructor for our effect type.
logMessage :: (Member Terminal r) => String -> Eff r ()
logMessage = send . LogMessage
getInputLine :: (Member Terminal r) => Eff r String
getInputLine = send GetInputLineInterpretations
At this point, you're probably wondering "hmmmm...when do we make these functions concrete"? After all, we haven't used putStrLn yet or anything like that. The answer is that we write an interpretation of the effect type, using a particular monad. This function will assume that our Terminal effect is on top of the effect stack, and it will "peel" that layer off, returning an action that no longer has the effect on the stack.
We call this function runTerminalIO because for this interpretation, we'll assume we are using the IO monad. And hence we will add a constraint that the IO monad is on the remaining stack r.
runTerminalIO :: (Member IO r) => Eff (Terminal ': r) a -> Eff r a
runTerminalIO = ...To fill in this function, we create a natural transformation between a Terminal action and an IO action. For the LogMessage constructor of course we'll use putStrLn, and for GetInputLine we'll use getLine.
runTerminalIO :: (Member IO r) => Eff (Terminal ': r) a -> Eff r a
runTerminalIO = ...
where
terminalToIO :: Terminal a -> IO a
terminalToIO (LogMessage msg) = putStrLn msg
terminalToIO GetInputLine = getLineThen to complete the function, we use runNat, a library function, together with this transformation.
runTerminalIO :: (Member IO r) => Eff (Terminal ': r) a -> Eff r a
runTerminalIO = runNat terminalToIO
where
terminalToIO :: Terminal a -> IO a
terminalToIO (LogMessage msg) = putStrLn msg
terminalToIO GetInputLine = getLineInterpreting the Full Stack
Now our complete effect stack will include this Terminal effect, the State effect, and the IO monad. This final stack is like our GameMonad. We'll need to write a concrete function to turn this in to a normal IO action.
transformGame :: Eff '[ Terminal, State (Player, Int), IO ] a -> IO a
transformGame = runM . (runNatS (Player1, 0) stateToIO) . runTerminalIO
where
stateToIO :: (Player, Int) -> State (Player, Int) a -> IO ((Player, Int), a)
stateToIO prev act = let (a', nextState) = runState act prev in return (nextState, a')This function is a bit like our other interpretation function in that it includes a transformation of the state layer. We combine this with our existing runTerminalIO function to get the final interpretation. Instead of runNat, we use runNatS to assign an initial state and allow that state to pass through to other calls.
Final Tweaks
And now there are just a few more edits we need to make. Most importantly, we can change the type signatures of our different functions. They should be in the Eff monad, and for every monad class constraint we used before, we'll now include a Member constraint.
playGame :: Eff '[ Terminal, State (Player, Int), IO ] Player
validateMove :: (Member Terminal r, Member (State (Player, Int)) r) => String -> Eff r (Maybe Int)
promptPlayer :: (Member Terminal r, Member (State (Player, Int)) r) => Eff r ()
readInput :: (Member Terminal r) => Eff r StringThat's most all of what we need to do! We also have to change the direct get and put calls to use getState and putState, but that's basically it! We can rebuild and play our game again now!
Conclusion: Effectful Haskell!
Now I know this overview was super quick so I could barely scratch the surface of how free monads work and what their benefits are. If you think these sound really cool though, and you want to learn this concept more in depth and get some hands on experience, you should sign up for our Effectful Haskell Course!
This course will teach you all the ins and outs of how Haskell allows you to structure effects, including how to do it with free monads. You'll get to see how these ideas work in the context of a decently-sized project. Even better is that you can get a 20% discount on it by subscribing to Monday Morning Haskell. So don't miss out, follow that link and get learning today!
Using IO without the IO Monad!

(This post is also available as a YouTube video!)
In last week's article, I explained what effects really are in the context of Haskell and why Haskell's structures for dealing with effects are really cool and distinguish it from other programming languages.
Essentially, Haskell's type system allows us to set apart areas of our code that might require a certain effect from those that don't. A function within a particular monad can typically use a certain effect. Otherwise, it can't. And we can validate this at compile time.
But there seems to be a problem with this. So many of Haskell's effects all sort of fall under the umbrella of the IO monad. Whether that's printing to the terminal, or reading from the file system, using threads and concurrency, connecting over the network, or even creating a new random number generator.
putStrLn :: String -> IO ()
readFile :: FilePath -> IO String
readMVar :: MVar a -> IO a
httpJSON :: (MonadIO m, FromJSON a) => Request -> m (Response a)
getStdGen :: MonadIO m => m StdGenNow I'm not going to tell you "oh just re-write your program so you don't need as much IO." These activities are essential to many programs. And often, they have to be spread throughout your code.
But the IO monad is essentially limitless in its abilities. If your whole program uses the IO monad, you essentially don't have any of the guarantees that we'd like to have about limiting side effects. If you need any kind of IO, it seems like you have to allow all sorts of IO.
But this doesn't have to be the case. In this article we're going to demonstrate how we can get limited IO effects within our function. That is, we'll write our type signature to allow a couple specific IO actions, without opening the door to all kinds of craziness. Let's see how this works.
An Example Game
Throughout this video we're going to be using this Nim game example I made. You can see all the code in Game.hs.
Our starting point for this article is the instances branch.
The ending point is the monad-class branch.
You can take a look at this pull request to see all the changes we're going to make in this article!
This program is a simple command line game where players are adding numbers to a sum and want to be the one to get to exactly 100. But there are some restrictions. You can't add more than 10, or add a negative number, or add too much to put it over 100. So if we try to do that we get some of these helpful error messages. And then when someone wins, we see who that is.
Our Monad
Now there's not a whole lot of code to this game. There are just a handful of functions, and they mostly live in this GameMonad we created. The "Game Monad" keeps track of the game state (a tuple of the current player and current sum value) using the State monad. Then it also uses the IO monad below that, which we need to receive user input and print all those messages we were seeing.
newtype GameMonad a = GameMonad
{ gameAction :: StateT (Player, Int) IO a
} deriving (Functor, Applicative, Monad)We have a couple instances, MonadState, and MonadIO for our GameMonad to make our code a bit simpler.
instance MonadIO GameMonad where
liftIO action = GameMonad (lift action)
instance MonadState (Player, Int) GameMonad where
get = GameMonad get
put = GameMonad . putNow the drawback here, as we talked about before, is that all these GameMonad functions can do arbitrary IO. We just do liftIO and suddenly we can go ahead and read a random file if we want.
playGame :: GameMonad Player
playGame = do
promptPlayer
input <- readInput
validateResult <- validateMove input
case validateResult of
Nothing -> playGame
Just i -> do
# Nothing to stop this!
readResult <- liftIO $ readFile "input.txt"
...Making Our Own Class
But we can change this with just a few lines of code. We'll start by creating our own typeclass. This class will be called MonadTerminal. It will have two functions for interacting with the terminal. First, logMessage, that will take a string and return nothing. And then getInputLine, that will return a string.
class MonadTerminal m where
logMessage :: String -> m ()
getInputLine :: m StringHow do we use this class? Well we have to make a concrete instance for it. So let's make an instance for our GameMonad. This will just use liftIO and run normal IO actions like putStrLn and getLine.
instance MonadTerminal GameMonad where
logMessage = liftIO . putStrLn
getInputLine = liftIO getLineConstraining Functions
At this point, we can get rid of the old logMessage function, since the typeclass uses that name now. Next, let's think about the readInput expression.
readInput :: GameMonad String
readInput = liftIO getLineIt uses liftIO and getLine right now. But this is exactly the same definition we used in MonadTerminal. So let's just replace this with the getInputLine class function.
readInput :: GameMonad String
readInput = getInputLineNow let's observe that this function no longer needs to be in the GameMonad! We can instead use any monad m that satisfies the MonadTerminal constraint. Since the GameMonad does this already, there's no effect on our code!
readInput :: (MonadTerminal m) => m String
readInput = getInputLineNow we can do the same thing with the other two functions. They call logMessage and readInput, so they require MonadTerminal. And they call get and put on the game state, so they need the MonadState constraint. But after doing that, we can remove GameMonad from the type signatures.
validateMove :: (MonadTerminal m, MonadState (Player, Int) m) => String -> m (Maybe Int)
...
promptPlayer :: (MonadTerminal m, MonadState (Player, Int) m) => m ()
...And now these functions can no longer use arbitrary IO! They're still using using the true IO effects we wrote above, but since MonadIO and GameMonad aren't in the type signature, we can't just call liftIO and do a file read.
Of course, the GameMonad itself still has IO on its Monad stack. That's the only way we can make a concrete implementation for our Terminal class that actually does IO!
But the actual functions in our game don't necessarily use the GameMonad anymore! They can use any monad that satisfies these two classes. And it's technically possible to write instances of these classes that don't use IO. So the functions can't use arbitrary IO functionality! This has a few different implications, but it especially gives us more confidence in the limitations of what these functions do, which as a reminder, is considered a good thing in Haskell! And it also allows us to test them more easily.
Conclusion: Effectful Haskell
Hopefully you think at least that this is a cool idea. But maybe you're thinking "Woah, this is totally game changing!" If you want to learn more about Haskell's effect structures, I have an offer for you!
If you head to this page you'll learn about our Effectful Haskell course. This course will give you hands-on experience working with the ideas from this video on a small but multi-functional application. The course starts with learning the different layers of Haskell's effect structures, and it ends with launching this application on the internet.
It's really cool, and if you've read this long, I think you'll enjoy it, so take a look! As a bonus, if you subscribe to Monday Morning Haskell, you can get a code for 20% off on this or any of our courses!
Why Haskell?

(This post is also available as a YouTube video!)
When I tell other programmers I do a lot of programming in Haskell, a common question is "Why"? What is so good about Haskell that it's worth learning a language that is so different from the vast majority of software. And there are a few different things I usually think of, but the biggest one that sticks out for me is the way Haskell structures effects. I think these structures have really helped me change the way I think about programming, and knowing these ideas has made me a more effective developer, even in other languages.
Defining Effects
Now you might be wondering, what exactly is an effect? Well to describe effects, let's first think about a "pure" function. A pure function has no inputs besides the explicit parameters, and the only way it impacts our program's behavior is through the value it returns.
// A simple, pure, function
public int addWith5(int x, int y) {
int result = x + y + 5;
return result;
}We can define an effect as, well, anything outside of that paradigm. This can be as simple as an implicit mutable input to the function like a global variable.
// Global mutable variable as in "implicit" input
global int z;
public int addWith5(int x, int y) {
int result = x + y + 5 + z; // < z isn't a function parameter!
return result;
}Or it can be something more complicated like writing something to the file system, or making an HTTP request to an API.
// More complicated effects (pseudo-code)
public int addWith5(int x, int y) {
int result = x + y + 5;
WriteFile("result.txt", result);
API.post(makeRequest(result));
return result;
}Once our function does these kinds of operations, its behavior is significantly less predictable, and that can cause a lot of bugs.
Now a common misconception about Haskell is that it does not allow side effects. And this isn't correct. What is true about Haskell is that if a function has side effects, these must be part of its type signature, usually in the form of a monad, which describes the full computational context of the function.
A function in the State monad can update a shared global value in some way.
updateValue :: Int -> State Int IntA function in the IO monad can write to the file system or even make a network call.
logAndSendRequest :: Req -> IO ResultDoing this type-level documentation helps avoid bugs and provide guarantees about parts of our program at compile time, and this can be a real lifesaver.
Re-thinking Code
In the last few years I've been writing about Haskell during my free time but using C++ and Python in my day job. And so I have a bigger appreciation for the lessons I learned from Haskell's effect structures and I've seen that my code in other languages is much better because I understand these lessons.
New Course: Effectful Haskell!
And this is why I'm excited to introduce my newest course on the Monday Morning Haskell Academy. This one is called Effectful Haskell, and I think it might be the most important course I've made so far, because it really zeroes in on this idea of effects. For me, this is the main idea that separates Haskell from other languages. But at the same time, it can also teach you to be a better programmer in these other languages.
This course is designed to give you hands-on experience with some of the different tools and paradigms Haskell has for structuring effects. It includes video lectures, screencasts, and in depth coding exercises that culminate with you launching a small but multi-functional web server.
If you've dabbled a bit in Haskell and you understand the core ideas, but you want to see what the language is really capable of, I highly recommend you try out this course. You can head to the course sales page to see an overview of the course as well as the FAQ. I'll mention a couple special items.
First, there is a 30-day refund guarantee if you decide you don't like the course.
And second, if you subscribe (or are already subscribed) to the Monday Morning Haskell newsletter, you'll get a 20% discount code for this and our other courses! So I hope you'll take a look and try it out.
Haskellings Demo Video!
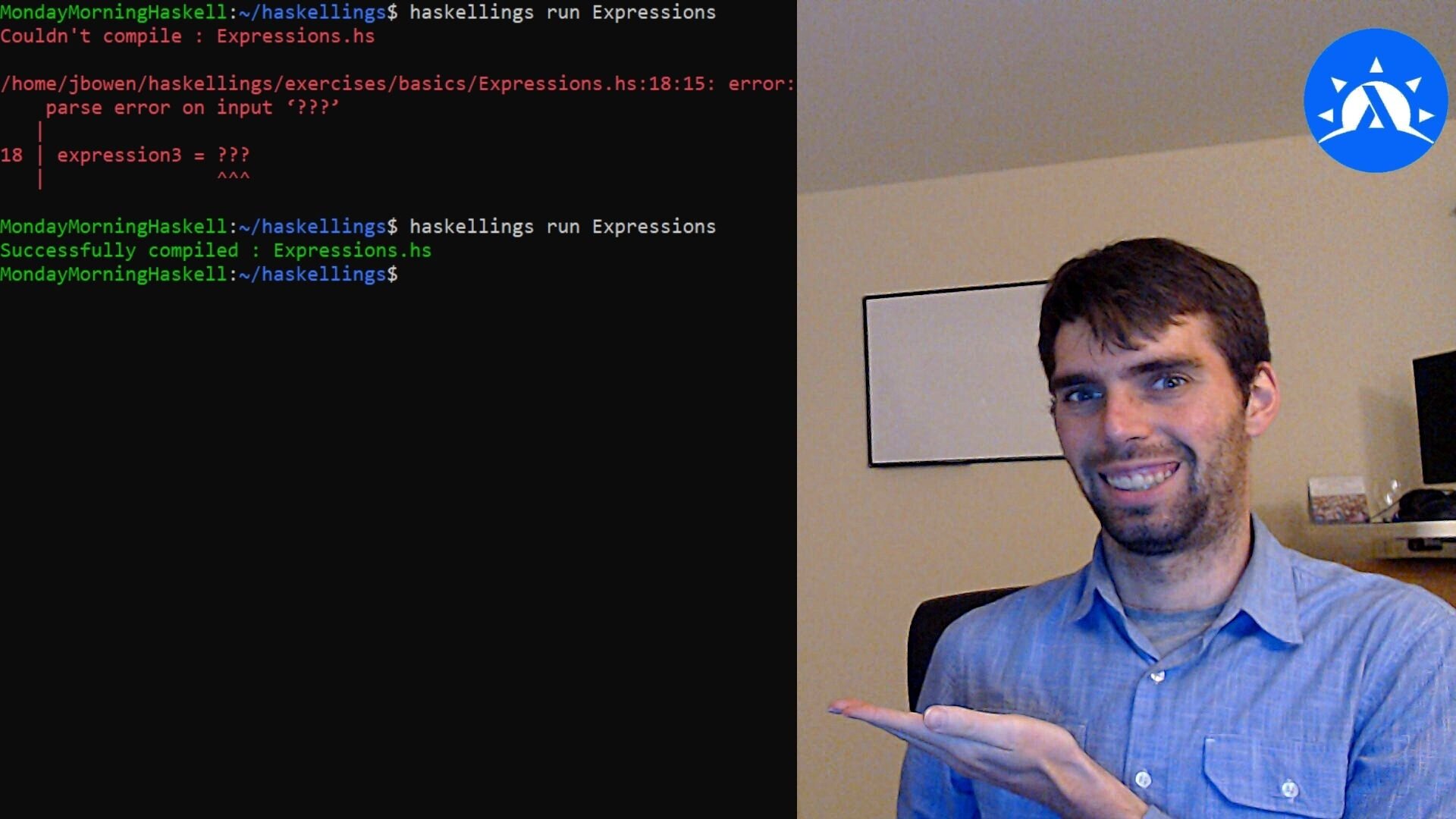
If you've been following my Twitch stream, you know I've been continuing to work quite a bit on the Haskellings automated tutorial. This week I'm releasing a short YouTube video demonstrating how to get started with this program and use it! If you've been waiting for the kick to get started with learning Haskell, this is it! Download Haskellings and get started!
And if you like it, don't forget to subscribe to Monday Morning Haskell for our subscriber-only resources!
Hpack in Video Form!

For a couple more weeks we'll be continuing with videos from recent streams! As a reminder you can catch me streaming on Twitch every Monday at 7:30 pm PDT (UTC-07). In the latest video, I walk through refactoring Haskellings to use Hpack instead of relying on the normal .cabal file format. Enjoy!
New Quicksort Video!

This week we've got a new video out! It goes in depth into the Quicksort algorithm. We compare implementations in Haskell and Python, and also consider what it really means for us to have an "In Place" algorithm that mutates our data.
I've written about this topic before, so check out these articles if you prefer written content!
But this new video includes some neat visuals showing Quicksort in action, so check it out!
Fixing Haskellings Filepaths
Hey folks! I'm experimenting with a new content format for Monday Morning Haskell. Every Monday Evening now, I'm going to stream myself writing some Haskell or working on a Haskell problem, and then the following Monday I'll post an overview of that stream on YouTube.
Last week was the first streaming session, where I was working on an issue with Haskellings. So this video will have some highlights from that. For broader context, I was looking to replace some custom functions I had built for filepath manipulation with the more well tested System.Filepath library.
This being the first stream, I hope you'll understand things are still a bit rough around the edges, but I hope you enjoy it! If you want to tune in to watch me on Monday Evenings, head over to my Twitch page!
Monday Evening Haskell!

We have an exciting announcement this week! Tonight, I'll be trying out a new form of content. I'll be streaming myself writing some Haskell. This will likely be a weekly event for quite a while. To see some Haskell in action, head to our Twitch Stream page from 7:30 PM until 9:30 PM Pacific Daylight Time (UTC-7).
Tonight's focus will be on updating Haskellings to use a library for file paths instead of its current custom system. The next few weeks will probably also be centered around Haskellings, but I'll also venture into some areas, like trying out some example coding problems with Haskell. I'll also change around the streaming time to give a chance to followers from around the world.
So don't miss out, head to our Twitch page, follow us, and tune in tonight at 7:30!
Summer Sale Ending!

Today is the last day of the Monday Morning Haskell summer sale! If you subscribe today, you'll get a discount code to use on all of our courses! This includes our new Making Sense of Monads course. If you're relatively new to Haskell, this is a great way to learn about this tricky topic that's a stumbling block for many newcomers. It's a short, one-module course covering these topics:
- Starting out with simpler functional structures (e.g. Functors)
- The syntactic elements involved in writing monadic functions
- The most common monads and how to combine them
- Bonus challenges to test your knowledge
You can get a closer overview of the content on the course page here. You can also look at our full course listings here. And if you subscribe today (July 26th) you'll get a discount code for all these courses! So don't wait!
Hidden Identity: Using the Identity Monad
Last week we announced our new Making Sense of Monads course. If you subscribe to our mailing list in the next week, you can get a special discount for this and our other courses! So don't miss out!
But in the meantime, we've got one more article on monads! Last week, we looked at the "Function monad". This week, we're going to explore another monad that you might not think about as much. But even if we don't specifically invoke it, this monad is actually present quite often, just in a hidden way! Once again, you can watch the video to learn more about this, or just read along below!
On its face, the identity monad is very simple. It just seems to wrap a value, and we can retrieve this value by calling runIdentity:
newtype Identity a = Identity { runIdentity :: a }So we can easily wrap any value in the Identity monad just by calling the Identity constructor, and we can unwrap it by calling runIdentity.
We can write a very basic instance of the monad typeclass for this type, that just incorporates wrapping and unwrapping the value:
instance Monad Identity where
return = Identity
(Identity a) >>= f = f aA Base Monad
So what's the point or use of this? Well first of all, let's consider a lot of common monads. We might think of Reader, Writer and State. These all have transformer variations like ReaderT, WriterT, and StateT. But actually, it's the "vanilla" versions of these functions that are the variations!
If we consider the Reader monad, this is actually a type synonym for a transformer over the Identity monad!
type Reader a = ReaderT Identity aIn this way, we don't need multiple abstractions to deal with "vanilla" monads and their transformers. The vanilla versions are the same as the transformers. The runReader function can actually be written in terms of runReaderT and runIdentity:
runReader :: Reader r a -> r -> a
runReader action = runIdentity . (runReaderT action)Using Identity
Now, there aren't that many reasons to use Identity explicitly, since the monad encapsulates no computational strategy. But here's one idea. Suppose that you've written a transformation function that takes a monadic action and runs some transformations on the inner value:
transformInt :: (Monad m) => m Int -> m (Double, Int)
transformInt action = do
asDouble <- fromIntegral <$> action
tripled <- (3 *) <$> action
return (asDouble, tripled)You would get an error if you tried to apply this to a normal unwrapped value. But by wrapping in Identity, we can reuse this function!
>> transformInt 5
Error!
>> transformInt (Identity 5)
Identity (5.0, 15)We can imagine the same thing with a function constraint using Functor or Applicative. Remember that Identity belongs to these classes as well, since it is a Monad!
Of course, it would be possible in this case to write a normal function that would accomplish the simple task in this example. But no matter how complex the task, we could write a version relying on the Identity monad that will always work!
transformInt' :: Int -> (Double, Int)
transformInt' = runIdentity . transformToInt . Identity
...
>> transformInt' 5
(5.0, 15)The Identity monad is just a bit of trivia regarding monads. If you've been dying to learn how to really use monads in your own programming, you should sign up for our new course Making Sense of Monads! For the next week you can subscribe to our mailing list and get a discount on this course as well as our other courses!
Making Sense of Monads!
We have a special announcement this week! We have a new course available at Monday Morning Haskell Academy! The course is called Making Sense of Monads, and as you might expect, it tackles the concept of monads! It's a short, one module course, but it goes into a good amount of detail about this vital topic, and includes a couple challenge projects at the end. Sign up here!. If you subscribe to our mailing list, you can get a special discount on this and our other courses!
In addition to this, we've also got some new blog content! Once again, there's a video, but you can also follow along by scrolling down!
Last week we discussed the function application operator, which I used for a long time as a syntactic crutch without really understanding it. This week we'll take another look at a function-related concept, but we'll relate it to our new monads course. We're going to explore the "function monad". That is, a single-argument function can act as a monad and call other functions which take the same input in a monadic fashion. Let's see how this works!
The Structure of Do Syntax
Let's start by considering a function in a more familiar monad like IO. Here's a function that queries the user for their name and writes it to a file.
ioFunc :: IO ()
ioFunc = do
putStrLn "Please enter your name"
name <- getLine
handle <- openFile "name.txt" WriteMode
hPutStrLn handle name
hClose handleDo syntax has a discernable structure. We can see this when we add all the type signatures in:
ioFunc :: IO String
ioFunc = do
putStrLn "Please enter your name" :: IO ()
(name :: String) <- getLine :: IO String
(handle :: Handle) <- openFile "name.txt" WriteMode :: IO Handle
hPutStrLn handle name :: IO ()
hClose handle :: IO ()
return name :: IO StringCertain lines have no result (returning ()), so they are just IO () expressions. Other lines "get" values using <-. For these lines, the right side is an expression IO a and the left side is the unwrapped result, of type a. And then the final line is monadic and must match the type of the complete expression (IO String in this case) without unwrapping it's result.
Here's how we might expression that pattern in more general terms, with a generic monad m:
combine :: a -> b -> Result
monadFunc :: m Result
monadFunc = do
(result1 :: a) <- exp1 :: m a
(result2 :: b) <- exp2 :: m b
exp3 :: m ()
return (combine result1 result2) :: m ResultUsing a Function
It turns out there is also a monad instance for (->) r, which is to say, a function taking some type r. To make this more concrete, let's suppose the r type is Int. Let's rewrite that generic expression, but instead of expressions like m Result, we'll instead have Int -> Result.
monadFunc :: Int -> Result
monadFunc = do
(result1 :: a) <- exp1 :: Int -> a
(result2 :: b) <- exp2 :: Int -> b
exp3 :: Int -> ()
return (combine result1 result2) :: Int -> ResultSo on the right, we see an expression "in the monad", like Int -> a. Then on the left is the "unwrapped" expression, of type a! Let's make this even more concrete! We'll remove exp3 since the function monad can't have any side effects, so a function returning () can't do anything the way IO () can.
monadFunc :: Int -> Int
monadFunc = do
result1 <- (+) 5
result2 <- (+) 11
return (result1 * result2)And we can run this function like we could run any other Int -> Int function! We don't need a run function like some other functions (Reader, State, etc.).
>> monadFunc 5
160
>> monadFunc 10
315Each line of the function uses the same input argument for its own input!
Now what does return mean in this monadic context? Well the final expression we have there is a constant expression. It must be a function to fit within the monad, but it doesn't care about the second input to the function. Well this is the exact definition of the const expression!
const :: a -> b -> a
const a _ = a -- Ignore second input!So we could replace return with const and it would still work!
monadFunc :: Int -> Int
monadFunc = do
result1 <- (+) 5
result2 <- (+) 11
const (result1 * result2)Now we could also use the implicit input for the last line! Here's an example where we don't use return:
monadFunc :: Int -> Int
monadFunc = do
result1 <- (+) 5
result2 <- (+) 11
(+) (result1 * result2)
...
>> monadFunc 5
165
>> monadFunc 10
325And of course, we could define multiple functions in this monad and call them from one another:
monadFunc2 :: Int -> String
monadFunc2 = do
result <- monadFunc
showInput <- show
const (show result ++ " " ++ showInput)Like a Reader?
So let's think about this monad more abstractly. This monadic unit gives us access to a single read-only input for each computation. Does this sound familiar to you? This is actually exactly like the Reader monad! And, in fact, there's an instance of the MonadReader typeclass for the function monad!
instance MonadReader r ((->) r) where
...So without changing anything, we can actually call Reader functions like local! Let's rewrite our function from above, except double the input for the call to monadFunc:
monadFunc2 :: Int -> String
monadFunc2 = do
result <- local (*2) monadFunc
showInput <- show
const (show result ++ " " ++ showInput)
...
>> func2 5
"325 5"
>> func2 10
"795 10"This isomorphism is one reason why you might not use the function monad explicitly so much. The Reader monad is a bit more canonical and natural. But, it's still useful to have this connection in mind, because it might be useful if you have a lot of different functions that take the same input!
If you're not super familiar with monads yet, hopefully this piqued your interest! To learn more, you can sign up for Making Sense of Monads! And if you subscribe to Monday Morning Haskell you can get a special discount, so don't wait!
Function Application: Using the Dollar Sign ($)
Things have been a little quiet here on the blog lately. We've got a lot of different projects going on behind the scenes, and we'll be making some big announcements about those soon! If you want to stay up to date with the latest news, make sure you subscribe to our mailing list! You'll get access to our subscriber-only resources, including our Beginners Checklist and our Production Checklist!
The next few posts will include a video as well as a written version! So you can click the play button below, or scroll down further to read along!
Let's talk about one of the unsung heroes, a true foot soldier of the Haskell language: the function application operator, ($). I used this operator a lot for a long time without really understanding it. Let's look at its type signature and implementation:
infixr 0
($) :: (a -> b) -> a -> b
f $ a = f aFor the longest time, I treated this operator as though it were a syntactic trick, and didn't even really think about it having a type signature. And when we look at this signature, it seems really basic. Quite simply, it takes a function, and an input to that function, and applies the function.
At first glance, this seems totally unnecessary! Why not just do "normal" function application by placing the argument next to the function?
add5 :: Int -> Int
add5 = (+) 5
-- Function application operator
eleven = add5 $ 6
-- Same result as "Normal" function application
eleven' = add5 6This operator doesn't let us write any function we couldn't write without it. But it does offer us some opportunities to organize our code a bit differently. And in some cases this is cleaner and it is more clear what is going semantically.
Grouping with $
Because its precedence is so low (level 0) this operator can let us do some kind of rudimentary grouping. This example doesn't compile, because Haskell tries to treat add5 as the second input to (+), rather than grouping it with 6, which appears to be its argument.
-- Doesn't compile!
value = (+) 11 add5 6We can group these together using parentheses. But the low precedence of ($) also allows it to act as a "separator". We break our expression into two groups. First we add and apply the first argument, and then we apply this function with the result of add5 6.
-- These work by grouping in different ways!
value = (+) 11 $ add5 6
value' = (+) 11 (add5 6)Other operators and function applications bind more tightly, so can have expressions like this:
value = (+) 11 $ 6 + 7 * 11 - 4A line with one $ essentially says "get the result of everything to the right and apply it as one final argument". So we calculate the result on the right (79) and then perform (+) 11 with that result.
Reordering Operations
The order of application also reverses with the function application operator as compared to normal function application. Let's consider this basic multiplication:
value = (*) 23 15Normal function application orders the precedence from left-to-right. So we apply the argument 23 to the function (*), and then apply the argument 15 to the resulting function.
However, we'll get an error if we use $ in between the elements of this expression!
-- Fails!
value = (*) $ 23 $ 15This is because ($) orders from right-to-left. So it first tries to treat "23" as a function and apply "15" as its argument.
If you have a chain of $ operations, the furthest right expression should be a single value. Then each grouping to the left should be a function taking a single argument. Here's how we might make an example with three sections.
value = (*) 23 $ (+10) $ 2 + 3Higher Order Functions
Having an operator for function application also makes it convenient to use it with higher order functions. Let's suppose we're zipping together a list of functions with a list of arguments.
functions = [(+3), (*5), (+2)]
arguments = [2, 5, 7]The zipWith function is helpful here, but this first approach is a little clunky with a lambda:
results = zipWith (\f a -> f a) functions argumentsBut of course, we can just replace that with the function application operator!
results = zipWith ($) functions arguments
results = [5, 25, 9]So hopefully we know a bit more about the "dollar sign" now, and can use it more intelligently! Remember to subscribe to Monday Morning Haskell! There will be special offers for subscribers in the next few weeks, so you don't want to miss out!
Haskellings Beta!
We spent a few months last year building the groundwork for Haskellings in this YouTube series. Now after some more hard work, we're happy to announce that Haskellings is now available in the beta stage. This program is meant to be an interactive tutorial for learning the Haskell language. If you've never written a line of Haskell in your life, this program is designed to help you take those first steps! You can take a look at the Github repository to learn all the details of using it, but here's a quick overview.
Overview
Haskellings gives you the chance to write Haskell code starting from the very basics with a quick evaluation loop. It currently has 50 different exercises for you to work with. In each exercise, you can read about a Haskell concept, make appropriate modifications, and then run the code with a single command to check your work!
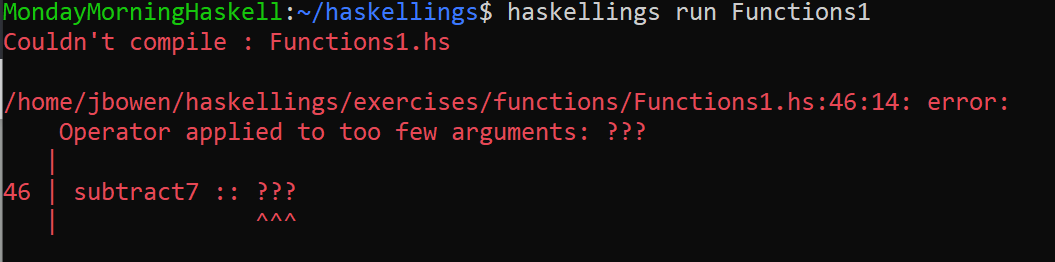

You can do exercises individually, but the easiest way to do everything in order is to run the program in Watcher mode. In this mode, it will automatically tell you which exercise is next. It will also re-run each exercise every time you save your work.

Haskellings covers a decent amount of ground on basic language concepts. It starts with the very basics of expressions, types and functions, and goes through the basic usage of monads.
Haskellings is an open source project! If you want to report issues or contribute, learn how by reading this document! So go ahead, give it a try!
Don't Forget: Haskell From Scratch
Haskellings is a quick and easy way to learn the language basics, but it only touches on the surface of a lot of elements. To get a more in-depth look at the language, you should consider our Haskell From Scratch video course. This course includes:
- Hours of video lectures explaining core language concepts and syntax
- Dozens of practice problems to help you hone your skills
- Access to our Slack channel, so you can get help and have your questions answered
- A final mini-project, to help you put the pieces together
This course will help you build a rock-solid foundation for your future Haskell learnings. And even better, we've now cut the price in half! So don't miss out!
Advanced Series Updated!

We're back again with some more site improvements, this time to our Advanced Content. All of these series now have improved syntax highlighting and code blocks for better readability. In addition, we've revised three of them with updated companion code! Here's a summary.
Real World Haskell Series
Once you've mastered the foundations of the language, this series should be your first stop! It will walk you through several different libraries demonstrating how you can perform some real-world tasks with Haskell, like connecting to a database and running a web server. You can follow along with all the code here on GitHub.
Parsing Series
As a functional language, Haskell thrives on being able to seemlessly compose smaller pieces of code together into a large, coherent whole. Parsing libraries are one area where this paradigm fits very well. In this series, we go through a few different parsing libraries and compare them. The code is available in this repository if you want to try it out yourself!
API Integrations Series
A lot of coding projects involved connected with outside services and APIs. Luckily, Haskell has a few libraries for interacting with these services! In this series, we'll explore integrations with Twilio and Mailgun so that we can send text messages and emails to your users! You can get a detailed breakdown of the code on GitHub. You can even fork the repository and run the code for yourself!
What's Coming Up?
Our next area of focus will be working on a first release of Haskellings, an interactive beginner tutorial for the language. We built this over the course of the last few months of 2020 in an extended video series that you can catch here on YouTube. The project is Open Source and currently available for contributions! Stay tuned for more updates on it!
Beginners Series Updated!

Where has Monday Morning Haskell been? Well, to ring in 2021, we've been making some big improvements to the permanent content on the site. So far we've focused on the Beginners section of the site. All the series here are updated with improved code blocks and syntax highlighting. In addition, we've fully revised most of them and added companion Github repositories so you can follow along!
Liftoff
Our Liftoff Series is our first stop for Haskell beginners. If you've never written a line of Haskell in your life but want to learn, this is the place to start! You can follow along with all the code in the series by using this Github repository.
Monads Series
Monads are a big "barrier" topic in Haskell. They don't really exist much in most other languages, but they're super important in Haskell. Our Monads Series breaks them down, starting with simpler functional structures so you can understand more easily! The code for this series can be found on Github here.
Testing Basics
You can't do serious production development in any language until you've mastered the basics of unit testing. Our Testing Series will school you on the basics of writing and running your first unit tests in Haskell. It'll also teach you about profiling your code so you can see improvements in its runtime! And you can follow along with the code right here on Github!
Haskell Data Basics
Haskell's data types are one of the first things that made me enjoy Haskell more than other languages. In this series we explore the ins and outs of Haskell's data declaration syntax and related topics like typeclasses. We compare it side-by-side with other languages and see how much easier it is to express certain concepts! Take a look at the code here!
What's Next?
Next up we'll be going through the same process for some of our more advanced series. So in the next couple weeks you can look forward to improvements there! Stay tuned!
Countdown to 2021!

At last. 2020 is nearly over. It's been a tumultuous year for the entire world, and I think most of us are glad to be turning over a new page, even if the future is still uncertain. As I always do, I'll sign off the year with a review of the different concepts we've looked at this year, and give a preview of what to expect in 2021.
2020 In Review
There were three major themes we covered this year. For much of the start of this year, we focused on AI. The main product of this was our work on a Haskell version of Open AI Gym. We explored ways to generalize the idea of an AI agent, including cool integrations of Haskell ideas like type families. We even wrote this in such a way that we could incorporate Tensor Flow! You can read about that work in our Open AI Series.
Over the summer, we switched gears a bit and focused on Rust. In our Rust Web Series we solved some more interesting problems to parallel our Real World Haskell Series. This included building a simple web server and connecting to a database.
Then our final work area was on our Haskellings program. Modeled after Rustlings, this is intended to be an automated beginner tutorial for the Haskell language. For the first time, I changed up the content a bit and did a video series, rather than a written blog series. So you can find the videos for that series on our YouTube Channel!
We're looking for people to contribute exercises (and possibly other code) to the Haskellings project, so definitely visit the repository if you'd like to help!
Looking Forward
There will be some big changes to the blog in 2021. Here are some of the highlights I'm looking forward to:
Spending more time on how Haskell fits into the broader programming ecosystem and what role it can play for those new to the industry. What can beginning programmers learn from the Haskell language and toolchain? What lessons of Haskell are applicable across many different languages? More exploration of different content types and media. As mentioned above, I spent the last part of 2020 experimenting with video blogs. I expect to do more of this type of experimenting this year. Upgrading the site's appearance and organization. Things have been pretty stagnant for a while, and there are a lot of improvements I'd like to make. For one example, I'd like to make coding sections more clear and interactive in blog posts. New, lighter-weight course material. Right now, our course page has 2 rather large courses. This year I'm going to look at breaking the material in these out into smaller, more manageable chunks, as well as adding a couple totally new course offerings at this smaller size.
I've set a lot of these goals before and fallen short. Unfortunately, I've found that these priorities often get pushed aside due to my desire to publish new content weekly, as I've been doing for over 4 years now (how time flies!). But starting in 2021, I'm going to focus on quality over quantity. I do not plan on publishing every week, and a lot of the blogs I do publish will highlight improvements to old content, rather than being new, detailed technical tutorials. I hope these changes will take the most important content on the blog and make it much more useful to the intended audiences.
I also have a tendency of creating projects to demonstrate concepts, but leave the projects behind once I am done writing about those concepts. This year, I hope to take a couple of my projects, specifically Open AI Gym and the Haskellings Beginner Tutorial and turn them into polished products that other developers will want to use. This will take a lot of focused time and effort, but I think it will be worth it.
So even though you might not see a new post every Monday, never fear! Monday Morning Haskell is here to stay! I hope all of you have a happy and safe new year!
Open Sourcing Haskellings!

In the last couple months we've been working on "Haskellings", an automated Haskell tutorial inspired by Rustlings. This week, I'm happy to announce that this project is now open source! You can find the (very early) version here on Github. I'll be working on making the project more complete throughout 2021, but I would really value any contributions the community has to this project! In this article, I'll list a few specific areas that would be good to work on!
More Exercises
The first and most important thing is that we need more exercises! I've done a couple simple examples to get started, but I'd like to crowd-source the creation of exercises. You can use the set of Rustlings exercises as some sort of inspiration. The most important topics to start out with would be things that explain the Haskell type system, so the different sorts of types, expressions and functions, as well as making our own data types. Other good concepts include things like syntax elements (think "where" and "case") and type classes.
Operating System Compatibility
I've definitely cut a few corners when it comes to the MVP of this project. I've only been working on Linux, so it's quite possible that there are some Linux-specific assumptions in the file-system level code. There will need to be some testing of the application on Windows and Mac platforms, and some adjustments will likely be necessary.
GHC Precision
Another area that will need some attention is the configuration section. Is there a cleaner way to determine where the GHC executable lives? What about finding the package database that corresponds to our Stack snapshot? My knowledge of Stack and package systems is limited, so it's very likely that there are some edge cases where the logic doesn't work out.
Exercise Cleanup
Right now, we list all the exercises explicitly in the ExerciseList module. But they're listed in two different places in the file. It would be good to clean this up, and potentially even add a feature for automated detection of exercise features. For example, we can figure out the filename, the directory, and whether or not it's runnable just by examining the file at its path! Right now the only thing that would need to be specified in "code" would be the order of exercises and their hints.
Contributing
If you're interested in contributing to this project, you can fork the repository, put up a pull request, and email me at james@mondaymorninghaskell.me! I'll be working on this periodically throughout 2021, hoping to have a more complete version to publish by the end.